Flink interpreter for Apache Zeppelin
Overview
Apache Flink is an open source platform for distributed stream and batch data processing. Flink’s core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams. Flink also builds batch processing on top of the streaming engine, overlaying native iteration support, managed memory, and program optimization.
In Zeppelin 0.9, we refactor the Flink interpreter in Zeppelin to support the latest version of Flink. Only Flink 1.10+ is supported, old versions of flink won't work. Apache Flink is supported in Zeppelin with the Flink interpreter group which consists of the five interpreters listed below.
| Name | Class | Description |
|---|---|---|
| %flink | FlinkInterpreter | Creates ExecutionEnvironment/StreamExecutionEnvironment/BatchTableEnvironment/StreamTableEnvironment and provides a Scala environment |
| %flink.pyflink | PyFlinkInterpreter | Provides a python environment |
| %flink.ipyflink | IPyFlinkInterpreter | Provides an ipython environment |
| %flink.ssql | FlinkStreamSqlInterpreter | Provides a stream sql environment |
| %flink.bsql | FlinkBatchSqlInterpreter | Provides a batch sql environment |
Prerequisites
- Download Flink 1.10 for scala 2.11 (Only scala-2.11 is supported, scala-2.12 is not supported yet in Zeppelin)
Configuration
The Flink interpreter can be configured with properties provided by Zeppelin (as following table). You can also add and set other flink properties which are not listed in the table. For a list of additional properties, refer to Flink Available Properties.
| Property | Default | Description |
|---|---|---|
FLINK_HOME |
Location of flink installation. It is must be specified, otherwise you can not use flink in Zeppelin | |
HADOOP_CONF_DIR |
Location of hadoop conf, this is must be set if running in yarn mode | |
HIVE_CONF_DIR |
Location of hive conf, this is must be set if you want to connect to hive metastore | |
| flink.execution.mode | local | Execution mode of flink, e.g. local | yarn | remote |
| flink.execution.remote.host | Host name of running JobManager. Only used for remote mode | |
| flink.execution.remote.port | Port of running JobManager. Only used for remote mode | |
| flink.jm.memory | 1024 | Total number of memory(mb) of JobManager |
| flink.tm.memory | 1024 | Total number of memory(mb) of TaskManager |
| flink.tm.slot | 1 | Number of slot per TaskManager |
| local.number-taskmanager | 4 | Total number of TaskManagers in local mode |
| flink.yarn.appName | Zeppelin Flink Session | Yarn app name |
| flink.yarn.queue | default | queue name of yarn app |
| flink.webui.yarn.useProxy | false | whether use yarn proxy url as flink weburl, e.g. http://resource-manager:8088/proxy/application15833965980680004 |
| flink.webui.yarn.address | Set this value only when your yarn address is mapped to some other address, e.g. some cloud vender will map http://resource-manager:8088 to https://xxx-yarn.yy.cn/gateway/kkk/yarn |
|
| flink.udf.jars | Flink udf jars (comma separated), zeppelin will register udf in this jar automatically for user. These udf jars could be either local files or hdfs files if you have hadoop installed. The udf name is the class name. | |
| flink.udf.jars.packages | Packages (comma separated) that would be searched for the udf defined in flink.udf.jars. |
|
| flink.execution.jars | Additional user jars (comma separated), these jars could be either local files or hdfs files if you have hadoop installed. | |
| flink.execution.packages | Additional user packages (comma separated), e.g. org.apache.flink:flink-connector-kafka2.11:1.10,org.apache.flink:flink-connector-kafka-base2.11:1.10.0,org.apache.flink:flink-json:1.10.0 | |
| zeppelin.flink.concurrentBatchSql.max | 10 | Max concurrent sql of Batch Sql (%flink.bsql) |
| zeppelin.flink.concurrentStreamSql.max | 10 | Max concurrent sql of Stream Sql (%flink.ssql) |
| zeppelin.pyflink.python | python | Python binary executable for PyFlink |
| table.exec.resource.default-parallelism | 1 | Default parallelism for flink sql job |
| zeppelin.flink.scala.color | true | Whether display scala shell output in colorful format |
| zeppelin.flink.enableHive | false | Whether enable hive |
| zeppelin.flink.hive.version | 2.3.4 | Hive version that you would like to connect |
| zeppelin.flink.module.enableHive | false | Whether enable hive module, hive udf take precedence over flink udf if hive module is enabled. |
| zeppelin.flink.maxResult | 1000 | max number of row returned by sql interpreter |
flink.interpreter.close.shutdown_cluster |
true | Whether shutdown application when closing interpreter |
zeppelin.interpreter.close.cancel_job |
true | Whether cancel flink job when closing interpreter |
zeppelin.flink.job.check_interval |
1000 | Check interval (in milliseconds) to check flink job progress |
StreamExecutionEnvironment, ExecutionEnvironment, StreamTableEnvironment, BatchTableEnvironment
Zeppelin will create 6 variables as flink scala (%flink) entry point:
senv(StreamExecutionEnvironment),benv(ExecutionEnvironment)stenv(StreamTableEnvironment for blink planner)btenv(BatchTableEnvironment for blink planner)stenv_2(StreamTableEnvironment for flink planner)btenv_2(BatchTableEnvironment for flink planner)
And will create 6 variables as pyflink (%flink.pyflink or %flink.ipyflink) entry point:
s_env(StreamExecutionEnvironment),b_env(ExecutionEnvironment)st_env(StreamTableEnvironment for blink planner)bt_env(BatchTableEnvironment for blink planner)st_env_2(StreamTableEnvironment for flink planner)bt_env_2(BatchTableEnvironment for flink planner)
Blink/Flink Planner
There are 2 planners supported by Flink's table api: flink & blink.
- If you want to use DataSet api, and convert it to flink table then please use flink planner (
btenv_2andstenv_2). - In other cases, we would always recommend you to use
blinkplanner. This is also what flink batch/streaming sql interpreter use (%flink.bsql&%flink.ssql)
Check this page for the difference between flink planner and blink planner.
Execution mode (Local/Remote/Yarn/Yarn Application)
Flink in Zeppelin supports 4 execution modes (flink.execution.mode):
- Local
- Remote
- Yarn
- Yarn Application
Run Flink in Local Mode
Running Flink in Local mode will start a MiniCluster in local JVM. By default, the local MiniCluster will use port 8081, so make sure this port is available in your machine,
otherwise you can configure rest.port to specify another port. You can also specify local.number-taskmanager and flink.tm.slot to customize the number of TM and number of slots per TM,
because by default it is only 4 TM with 1 Slots which may not be enough for some cases.
Run Flink in Remote Mode
Running Flink in remote mode will connect to an existing flink cluster which could be standalone cluster or yarn session cluster. Besides specifying flink.execution.mode to be remote. You also need to specify
flink.execution.remote.host and flink.execution.remote.port to point to flink job manager.
Run Flink in Yarn Mode
In order to run flink in Yarn mode, you need to make the following settings:
- Set
flink.execution.modetoyarn - Set
HADOOP_CONF_DIRin flink's interpreter setting orzeppelin-env.sh. - Make sure
hadoopcommand is on your PATH. Because internally flink will call commandhadoop classpathand load all the hadoop related jars in the flink interpreter process
Run Flink in Yarn Application Mode
In the above yarn mode, there will be a separated flink interpreter process. This may run out of resources when there're many interpreter processes. So it is recommended to use yarn application mode if you are using flink 1.11 or afterwards (yarn application mode is only supported after flink 1.11). In this mode flink interpreter runs in the JobManager which is in yarn container. In order to run flink in yarn application mode, you need to make the following settings:
- Set
flink.execution.modetoyarn-application - Set
HADOOP_CONF_DIRin flink's interpreter setting orzeppelin-env.sh. - Make sure
hadoopcommand is on your PATH. Because internally flink will call commandhadoop classpathand load all the hadoop related jars in the flink interpreter process
How to use Hive
In order to use Hive in Flink, you have to make the following setting.
- Set
zeppelin.flink.enableHiveto be true - Set
zeppelin.flink.hive.versionto be the hive version you are using. - Set
HIVE_CONF_DIRto be the location wherehive-site.xmlis located. Make sure hive metastore is started and you have configuredhive.metastore.urisinhive-site.xml - Copy the following dependencies to the lib folder of flink installation.
- flink-connector-hive_2.11–1.10.0.jar
- flink-hadoop-compatibility_2.11–1.10.0.jar
- hive-exec-2.x.jar (for hive 1.x, you need to copy hive-exec-1.x.jar, hive-metastore-1.x.jar, libfb303–0.9.2.jar and libthrift-0.9.2.jar)
Flink Batch SQL
%flink.bsql is used for flink's batch sql. You can type help to get all the available commands.
It supports all the flink sql, including DML/DDL/DQL.
- Use
insert intostatement for batch ETL - Use
selectstatement for batch data analytics
Flink Streaming SQL
%flink.ssql is used for flink's streaming sql. You just type help to get all the available commands.
It supports all the flink sql, including DML/DDL/DQL.
- Use
insert intostatement for streaming ETL - Use
selectstatement for streaming data analytics
Streaming Data Visualization
Zeppelin supports 3 types of streaming data analytics: * Single * Update * Append
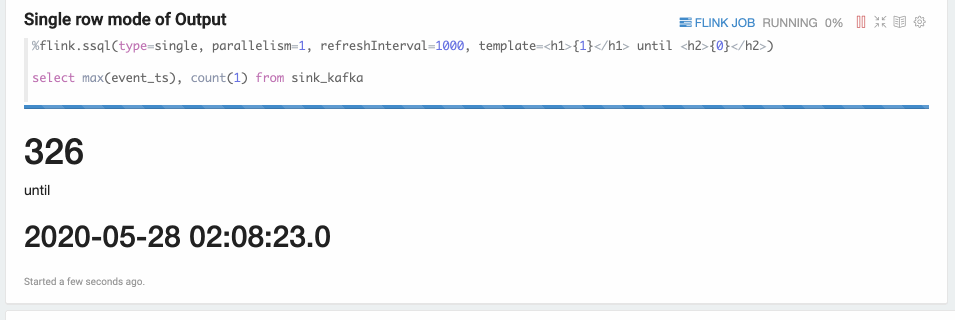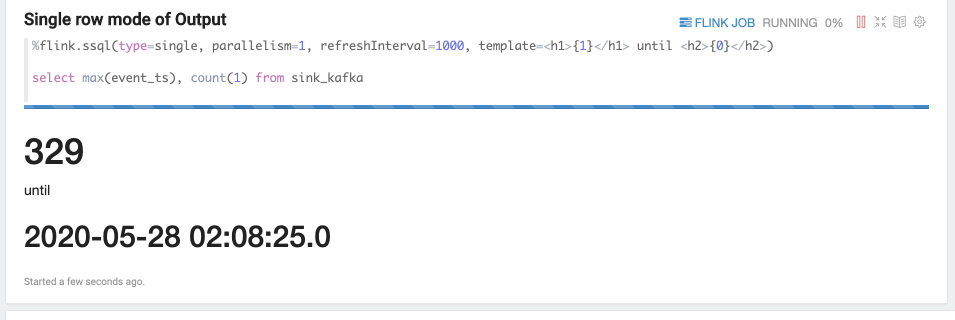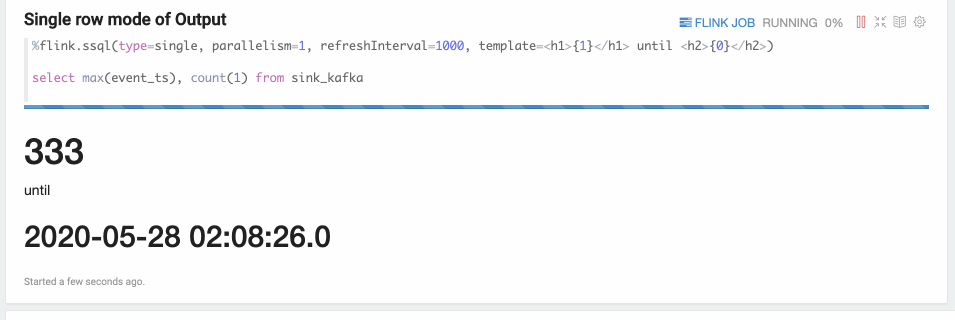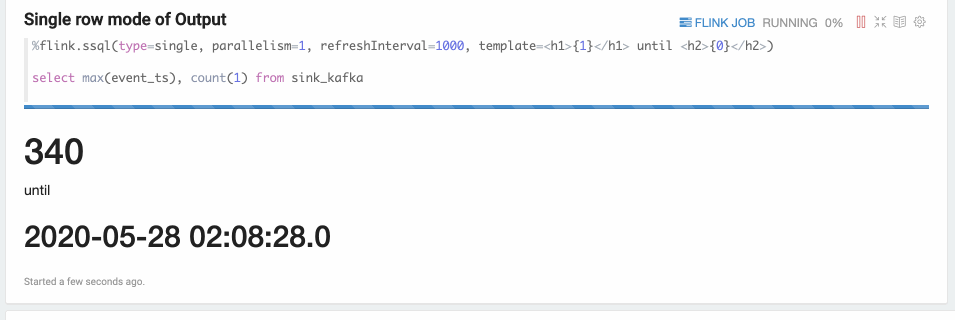
type=single
Single mode is for the case when the result of sql statement is always one row, such as the following example. The output format is HTML,
and you can specify paragraph local property template for the final output content template.
And you can use {i} as placeholder for the ith column of result.
type=update
Update mode is suitable for the case when the output is more than one rows, and always will be updated continuously. Here’s one example where we use group by.
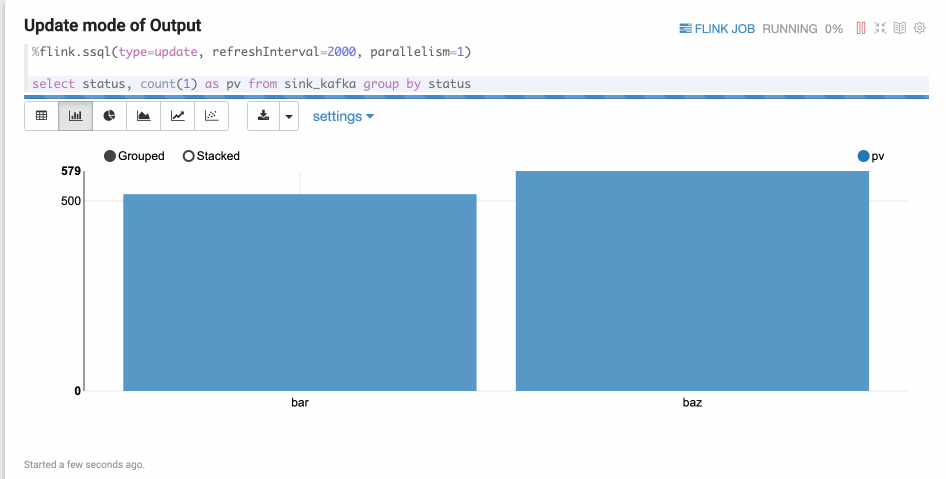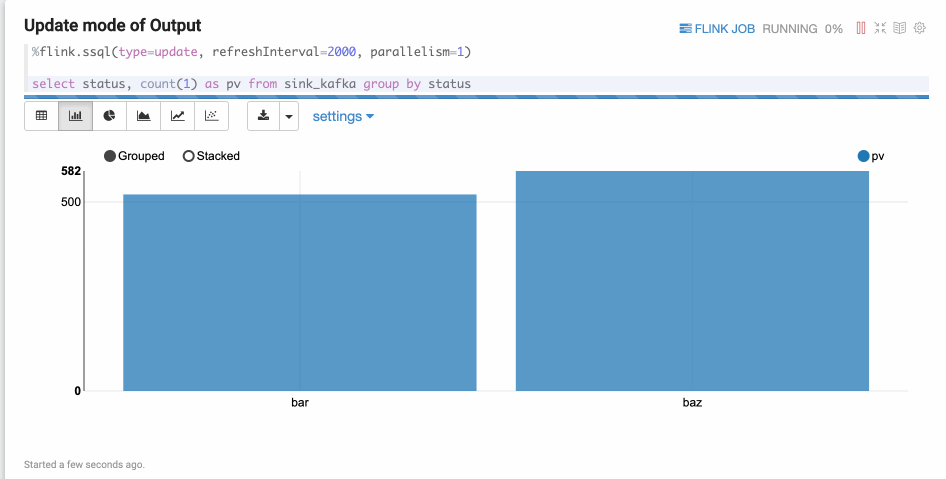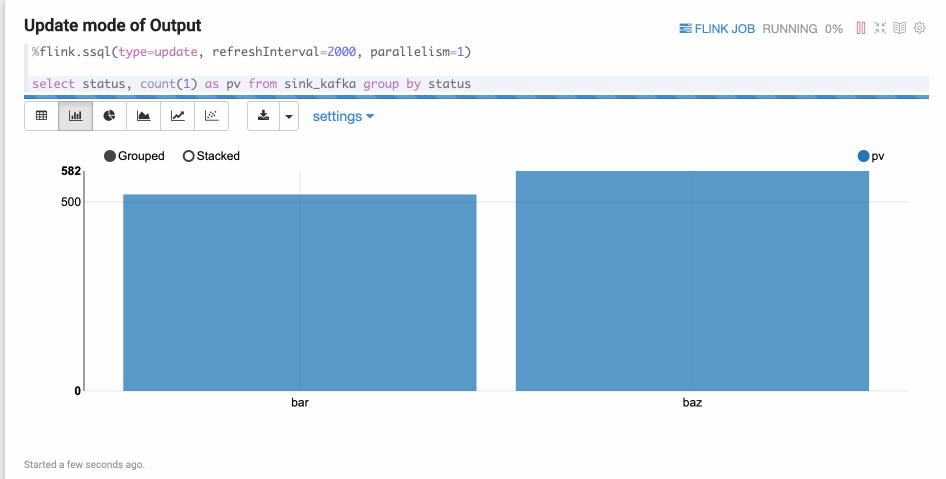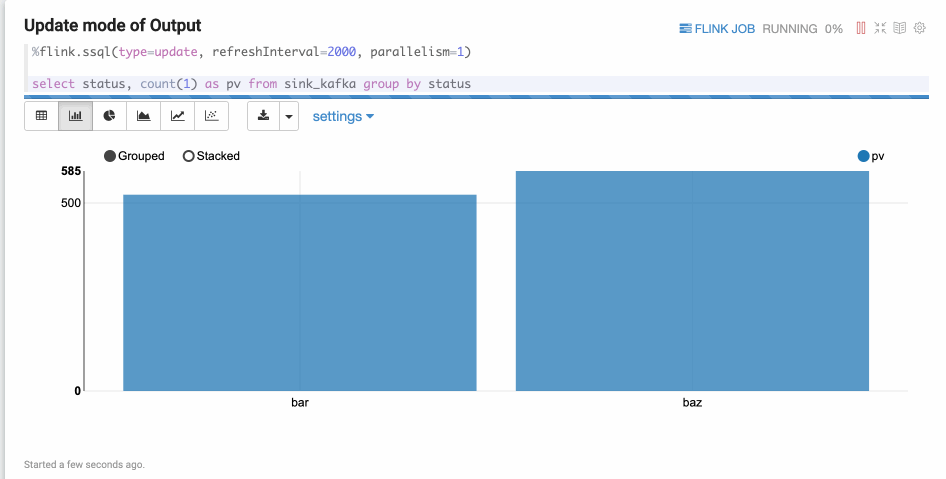
type=append
Append mode is suitable for the scenario where output data is always appended. E.g. the following example which use tumble window.
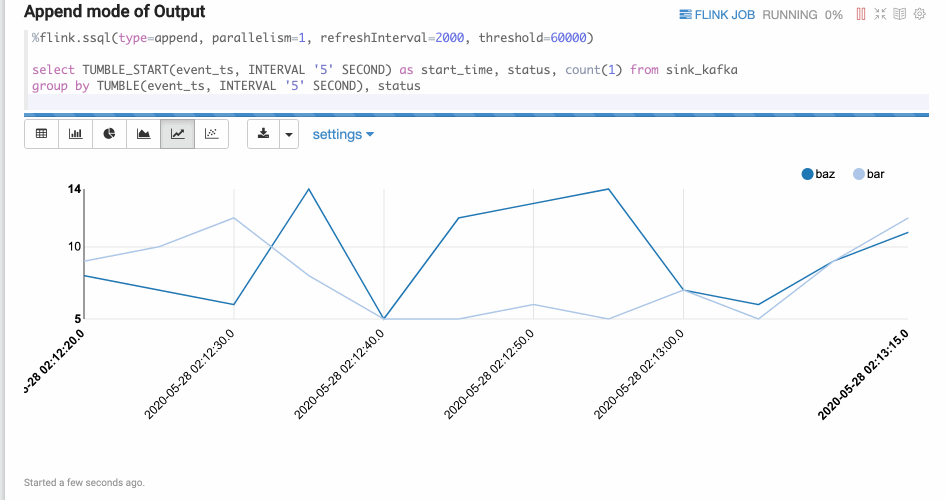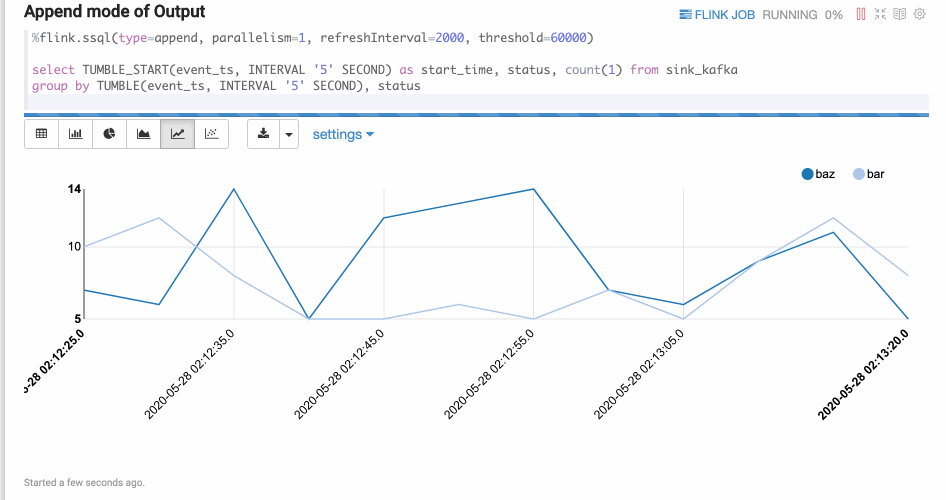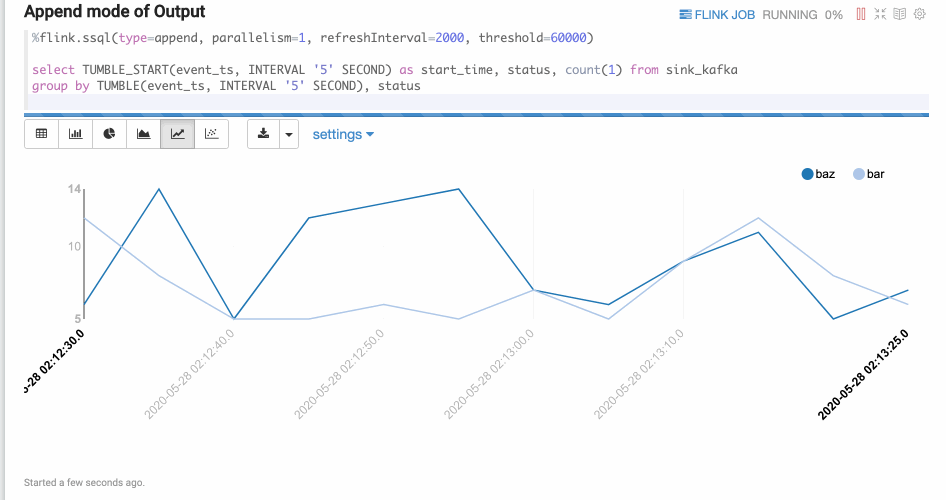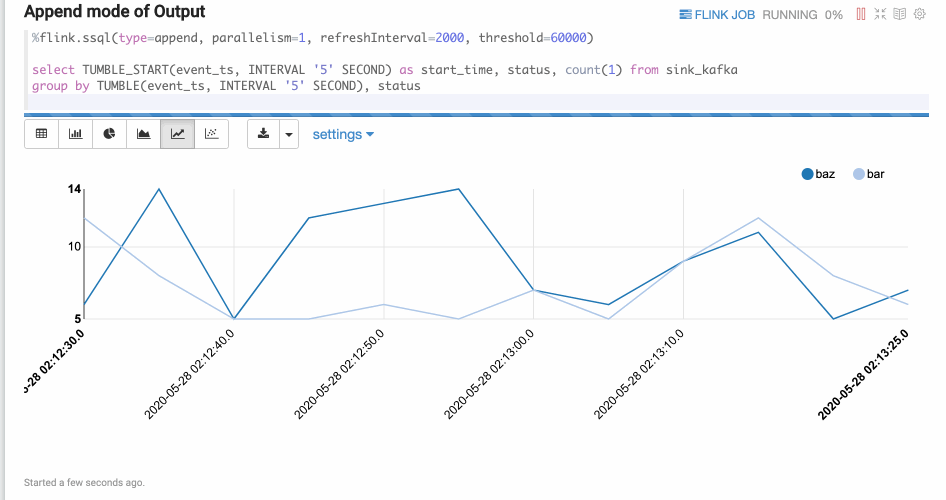
Flink UDF
You can use Flink scala UDF or Python UDF in sql. UDF for batch and streaming sql is the same. Here're 2 examples.
- Scala UDF
%flink
class ScalaUpper extends ScalarFunction {
def eval(str: String) = str.toUpperCase
}
btenv.registerFunction("scala_upper", new ScalaUpper())
- Python UDF
%flink.pyflink
class PythonUpper(ScalarFunction):
def eval(self, s):
return s.upper()
bt_env.register_function("python_upper", udf(PythonUpper(), DataTypes.STRING(), DataTypes.STRING()))
Zeppelin only supports scala and python for flink interpreter, if you want to write a java udf or the udf is pretty complicated which make it not suitable to write in Zeppelin,
then you can write the udf in IDE and build an udf jar.
In Zeppelin you just need to specify flink.udf.jars to this jar, and flink
interpreter will detect all the udfs in this jar and register all the udfs to TableEnvironment, the udf name is the class name.
PyFlink(%flink.pyflink)
In order to use PyFlink in Zeppelin, you just need to do the following configuration.
* Install apache-flink (e.g. pip install apache-flink)
* Set zeppelin.pyflink.python to the python executable where apache-flink is installed in case you have multiple python installed.
* Copy flink-python_2.11–1.10.0.jar from flink opt folder to flink lib folder
And PyFlink will create 6 variables for you:
s_env(StreamExecutionEnvironment),b_env(ExecutionEnvironment)st_env(StreamTableEnvironment for blink planner)bt_env(BatchTableEnvironment for blink planner)st_env_2(StreamTableEnvironment for flink planner)bt_env_2(BatchTableEnvironment for flink planner)
IPython Support(%flink.ipyflink)
By default, zeppelin would use IPython in %flink.pyflink when IPython is available, Otherwise it would fall back to the original python implementation.
For the IPython features, you can refer docPython Interpreter
ZeppelinContext
Zeppelin automatically injects ZeppelinContext as variable z in your Scala/Python environment. ZeppelinContext provides some additional functions and utilities.
See Zeppelin-Context for more details. You can use z to display both flink DataSet and batch/stream table.
Display DataSet
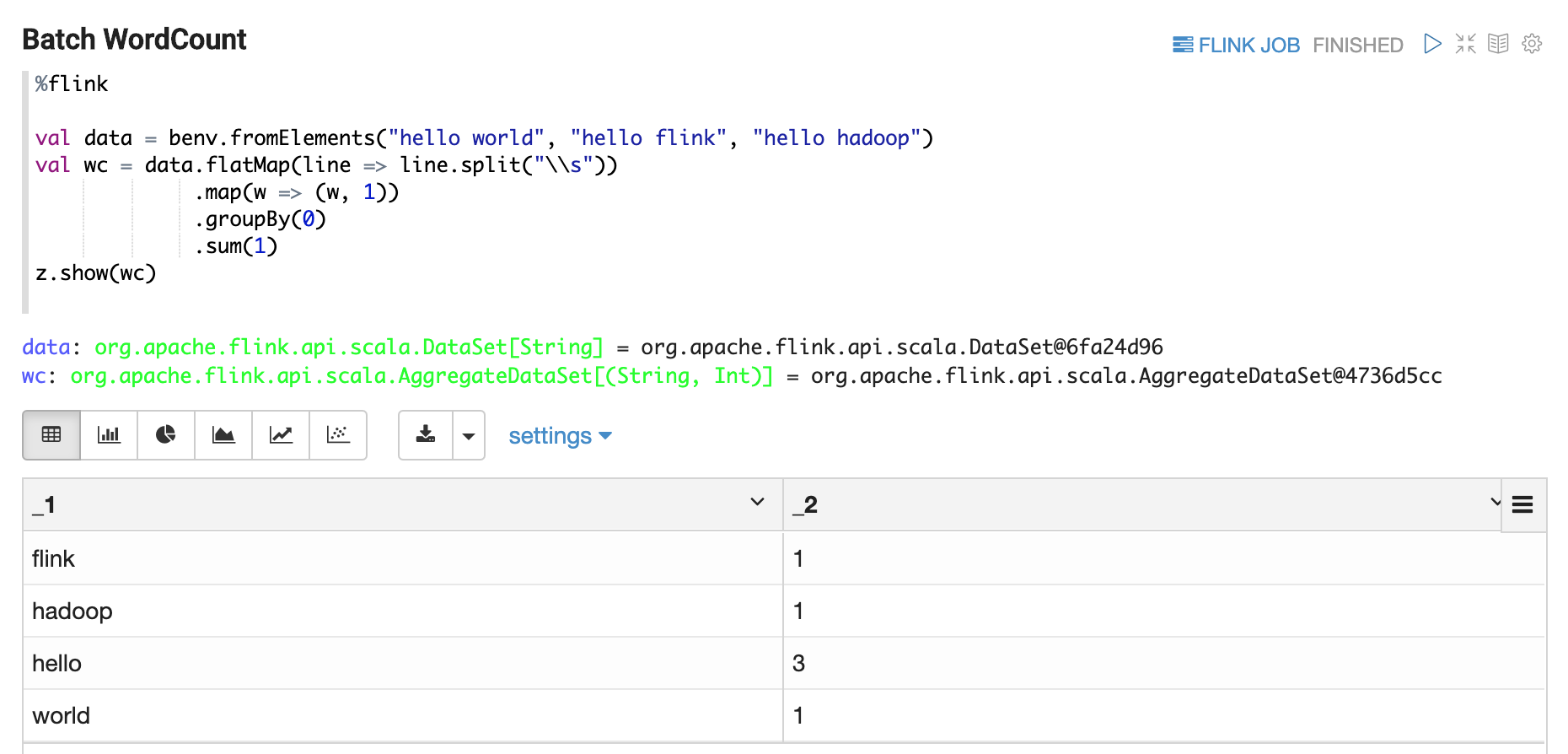
Display Batch Table
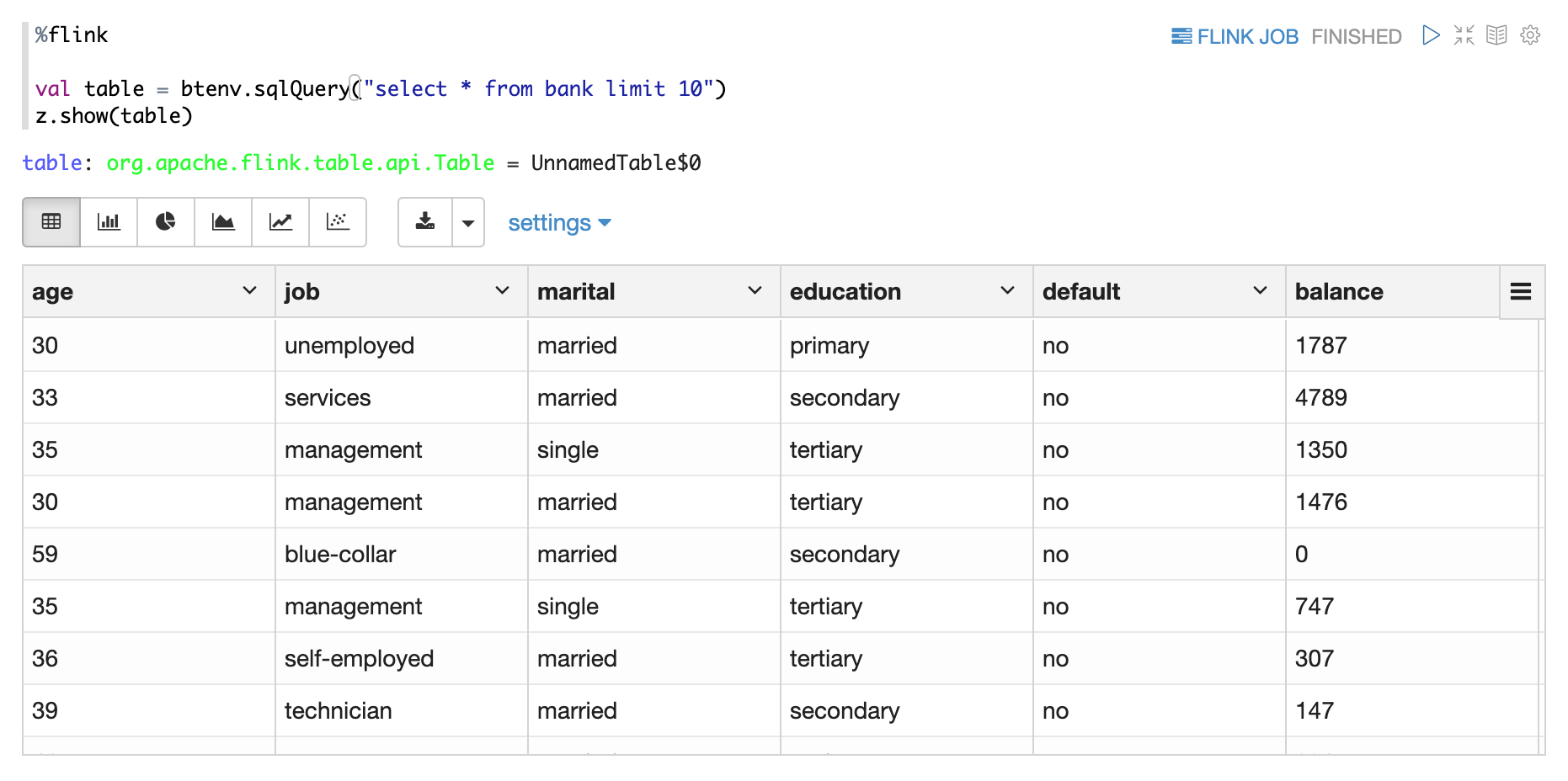
Display Stream Table
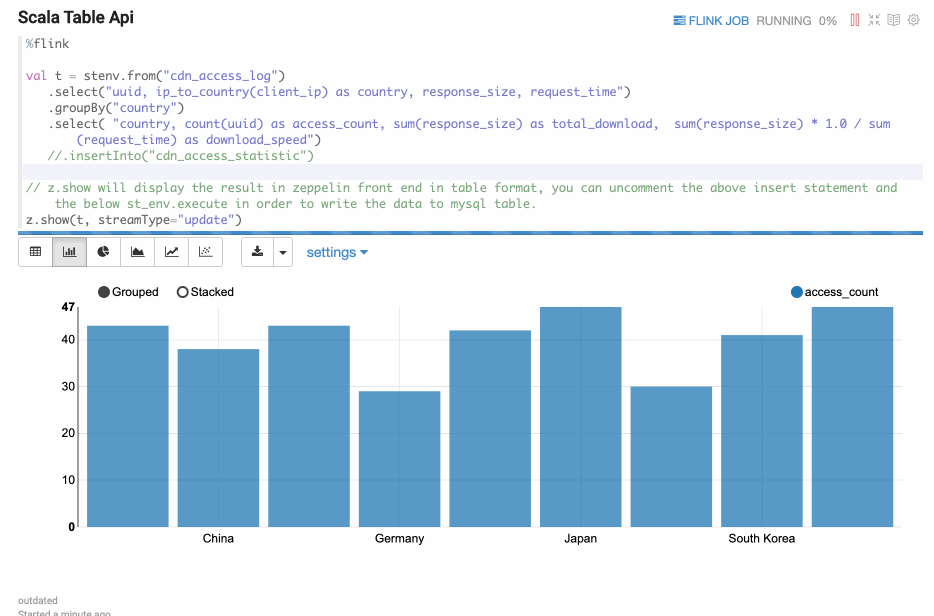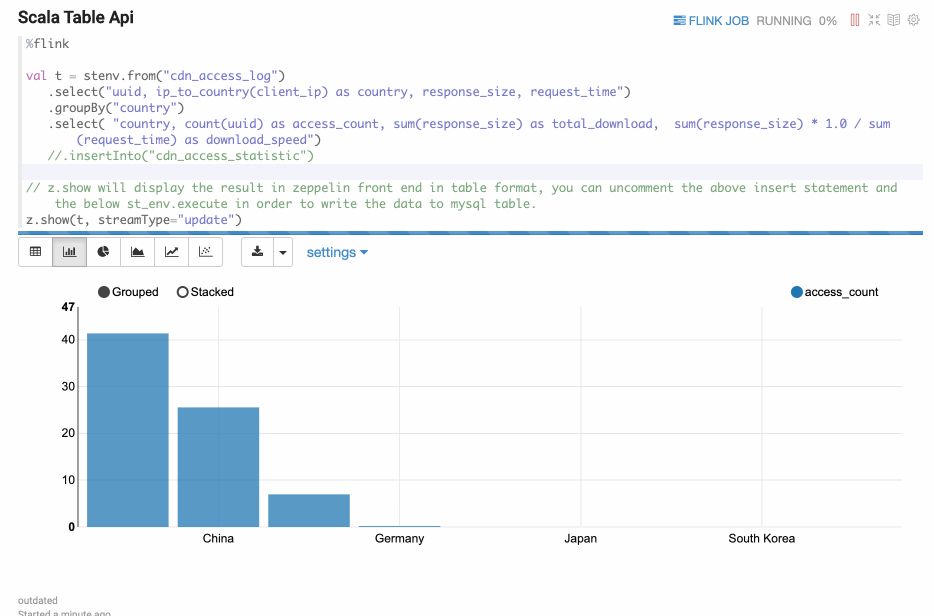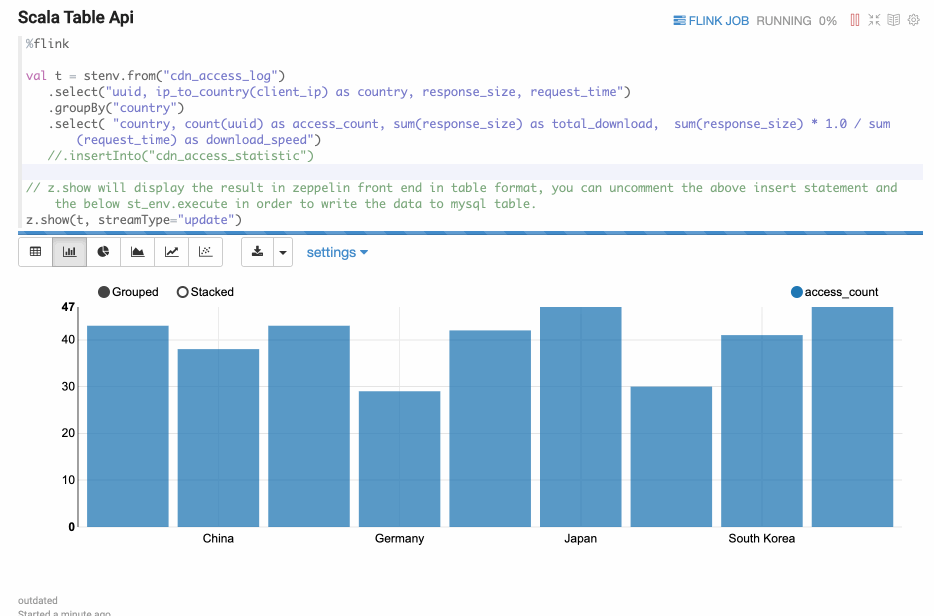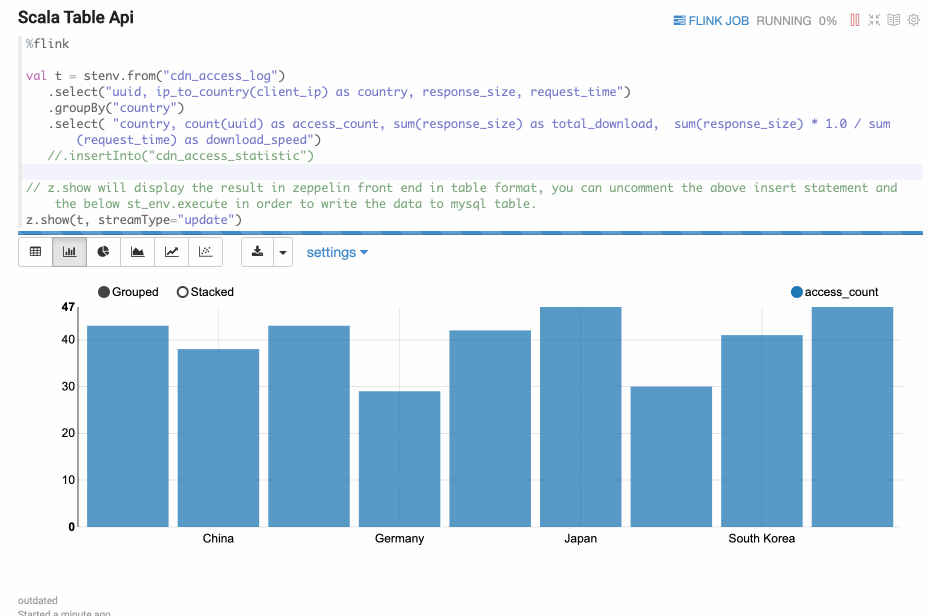
Paragraph local properties
In the section of Streaming Data Visualization, we demonstrate the different visualization type via paragraph local properties: type.
In this section, we will list and explain all the supported local properties in flink interpreter.
| Property | Default | Description |
|---|---|---|
| type | Used in %flink.ssql to specify the streaming visualization type (single, update, append) | |
| refreshInterval | 3000 | Used in `%flink.ssql` to specify frontend refresh interval for streaming data visualization. |
| template | {0} | Used in `%flink.ssql` to specify html template for `single` type of streaming data visualization, And you can use `{i}` as placeholder for the {i}th column of the result. |
| parallelism | Used in %flink.ssql & %flink.bsql to specify the flink sql job parallelism | |
| maxParallelism | Used in %flink.ssql & %flink.bsql to specify the flink sql job max parallelism in case you want to change parallelism later. For more details, refer this [link](https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/parallel.html#setting-the-maximum-parallelism) | |
| savepointDir | If you specify it, then when you cancel your flink job in Zeppelin, it would also do savepoint and store state in this directory. And when you resume your job, it would resume from this savepoint. | |
| execution.savepoint.path | When you resume your job, it would resume from this savepoint path. | |
| resumeFromSavepoint | Resume flink job from savepoint if you specify savepointDir. | |
| resumeFromLatestCheckpoint | Resume flink job from latest checkpoint if you enable checkpoint. | |
| runAsOne | false | All the insert into sql will run in a single flink job if this is true. |
Tutorial Notes
Zeppelin is shipped with several Flink tutorial notes which may be helpful for you. You can check for more features in the tutorial notes.