Submarine Interpreter for Apache Zeppelin
Hadoop Submarine is the latest machine learning framework subproject in the Hadoop 3.1 release. It allows Hadoop to support Tensorflow, MXNet, Caffe, Spark, etc. A variety of deep learning frameworks provide a full-featured system framework for machine learning algorithm development, distributed model training, model management, and model publishing, combined with hadoop's intrinsic data storage and data processing capabilities to enable data scientists to Good mining and the value of the data.
A deep learning algorithm project requires data acquisition, data processing, data cleaning, interactive visual programming adjustment parameters, algorithm testing, algorithm publishing, algorithm job scheduling, offline model training, model online services and many other processes and processes. Zeppelin is a web-based notebook that supports interactive data analysis. You can use SQL, Scala, Python, etc. to make data-driven, interactive, collaborative documents.
You can use the more than 20 interpreters in zeppelin (for example: spark, hive, Cassandra, Elasticsearch, HBase, etc.) to collect data, clean data, feature extraction, etc. in the data in Hadoop before completing the machine learning model training. The data preprocessing process.
By integrating submarine in zeppelin, we use zeppelin's data discovery, data analysis and data visualization and collaboration capabilities to visualize the results of algorithm development and parameter adjustment during machine learning model training.
Architecture
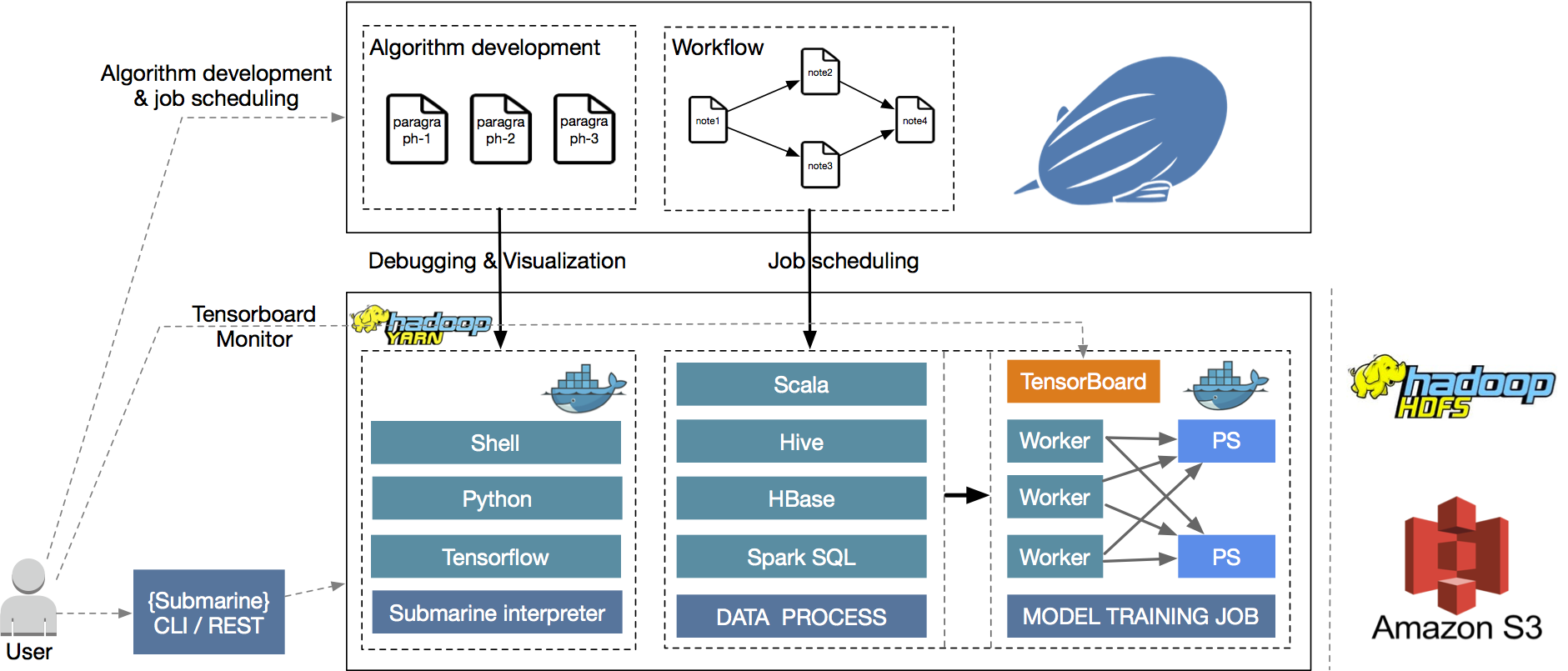
As shown in the figure above, how the Submarine develops and models the machine learning algorithms through Zeppelin is explained from the system architecture.
After installing and deploying Hadoop 3.1+ and Zeppelin, submarine will create a fully separate Zeppelin Submarine interpreter Docker container for each user in YARN. This container contains the development and runtime environment for Tensorflow. Zeppelin Server connects to the Zeppelin Submarine interpreter Docker container in YARN. allows algorithmic engineers to perform algorithm development and data visualization in Tensorflow's stand-alone environment in Zeppelin Notebook.
After the algorithm is developed, the algorithm engineer can submit the algorithm directly to the YARN in offline transfer training in Zeppelin, real-time demonstration of model training with Submarine's TensorBoard for each algorithm engineer.
You can not only complete the model training of the algorithm, but you can also use the more than twenty interpreters in Zeppelin. Complete the data preprocessing of the model, For example, you can perform data extraction, filtering, and feature extraction through the Spark interpreter in Zeppelin in the Algorithm Note.
In the future, you can also use Zeppelin's upcoming Workflow workflow orchestration service. You can complete Spark, Hive data processing and Tensorflow model training in one Note. It is organized into a workflow through visualization, etc., and the scheduling of jobs is performed in the production environment.
Overview

As shown in the figure above, from the internal implementation, how Submarine combines Zeppelin's machine learning algorithm development and model training.
The algorithm engineer created a Tensorflow notebook (left image) in Zeppelin by using Submarine interpreter.
It is important to note that you need to complete the development of the entire algorithm in a Note.
You can use Spark for data preprocessing in some of the paragraphs in Note.
Use Python for algorithm development and debugging of Tensorflow in other paragraphs of notebook, Submarine creates a Zeppelin Submarine Interpreter Docker Container for you in YARN, which contains the following features and services:
- Shell Command line tool:Allows you to view the system environment in the Zeppelin Submarine Interpreter Docker Container, Install the extension tools you need or the Python dependencies.
- Kerberos lib:Allows you to perform kerberos authentication and access to Hadoop clusters with Kerberos authentication enabled.
- Tensorflow environment:Allows you to develop tensorflow algorithm code.
- Python environment:Allows you to develop tensorflow code.
- Complete a complete algorithm development with a Note in Zeppelin. If this algorithm contains multiple modules, You can write different algorithm modules in multiple paragraphs in Note. The title of each paragraph is the name of the algorithm module. The content of the paragraph is the code content of this algorithm module.
HDFS Client:Zeppelin Submarine Interpreter will automatically submit the algorithm code you wrote in Note to HDFS.
Submarine interpreter Docker Image It is Submarine that provides you with an image file that supports Tensorflow (CPU and GPU versions). And installed the algorithm library commonly used by Python. You can also install other development dependencies you need on top of the base image provided by Submarine.
- When you complete the development of the algorithm module, You can do this by creating a new paragraph in Note and typing
%submarine dashboard. Zeppelin will create a Submarine Dashboard. The machine learning algorithm written in this Note can be submitted to YARN as a JOB by selecting theJOB RUNcommand option in the Control Panel. Create a Tensorflow Model Training Docker Container, The container contains the following sections:
- Tensorflow environment
HDFS Client Will automatically download the algorithm file Mount from HDFS into the container for distributed model training. Mount the algorithm file to the Work Dir path of the container.
Submarine Tensorflow Docker Image There is Submarine that provides you with an image file that supports Tensorflow (CPU and GPU versions). And installed the algorithm library commonly used by Python. You can also install other development dependencies you need on top of the base image provided by Submarine.
| Name | Class | Description |
|---|---|---|
| %submarine | SubmarineInterpreter | Provides interpreter for Apache Submarine dashboard |
| %submarine.sh | SubmarineShellInterpreter | Provides interpreter for Apache Submarine shell |
| %submarine.python | PySubmarineInterpreter | Provides interpreter for Apache Submarine python |
Submarine shell
After creating a Note with Submarine Interpreter in Zeppelin, You can add a paragraph to Note if you need it. Using the %submarine.sh identifier, you can use the Shell command to perform various operations on the Submarine Interpreter Docker Container, such as:
- View the Pythone version in the Container
- View the system environment of the Container
- Install the dependencies you need yourself
- Kerberos certification with kinit
- Use Hadoop in Container for HDFS operations, etc.
Submarine python
You can add one or more paragraphs to Note. Write the algorithm module for Tensorflow in Python using the %submarine.python identifier.
Submarine Dashboard
After writing the Tensorflow algorithm by using %submarine.python, You can add a paragraph to Note. Enter the %submarine dashboard and execute it. Zeppelin will create a Submarine Dashboard.
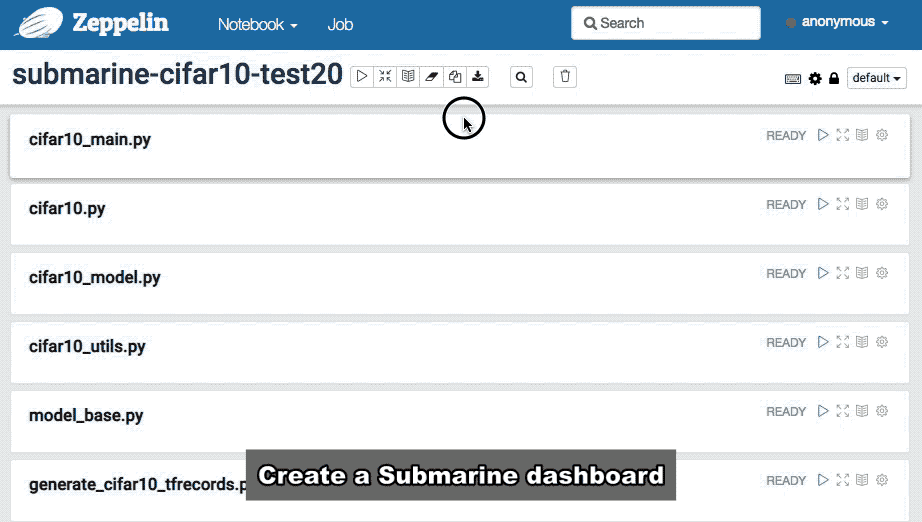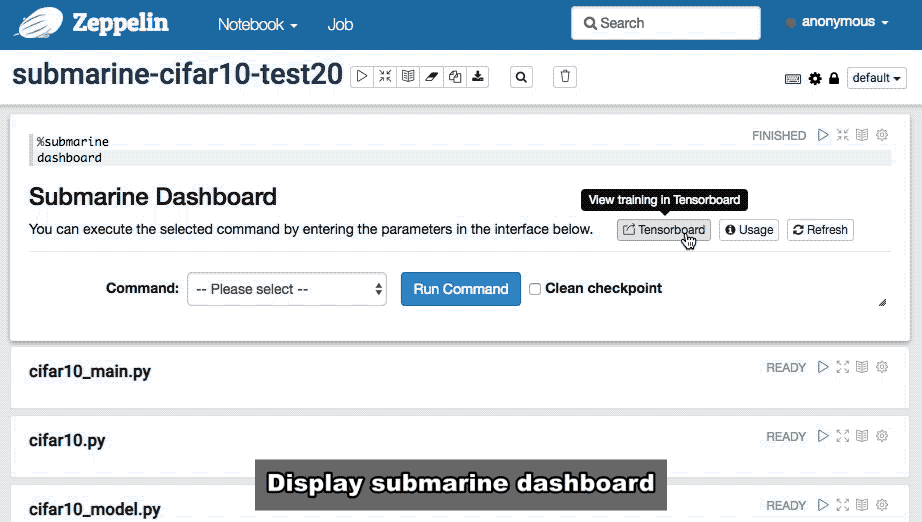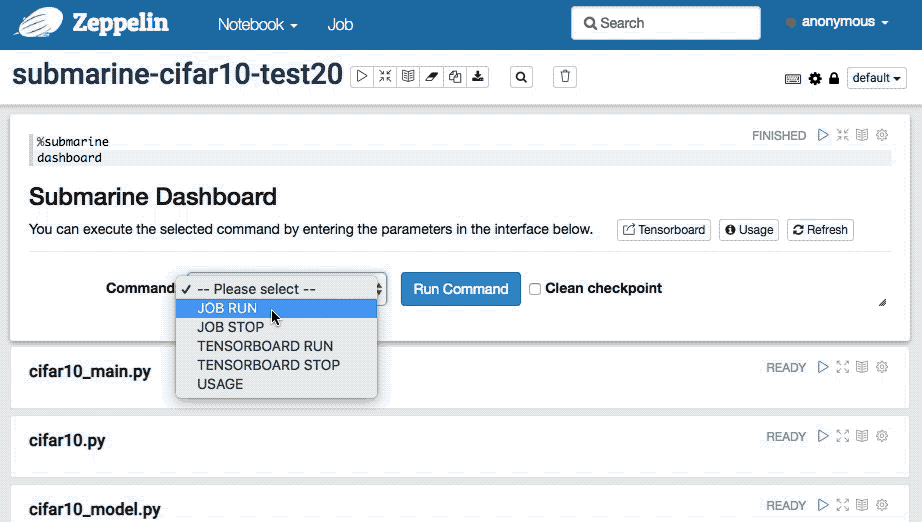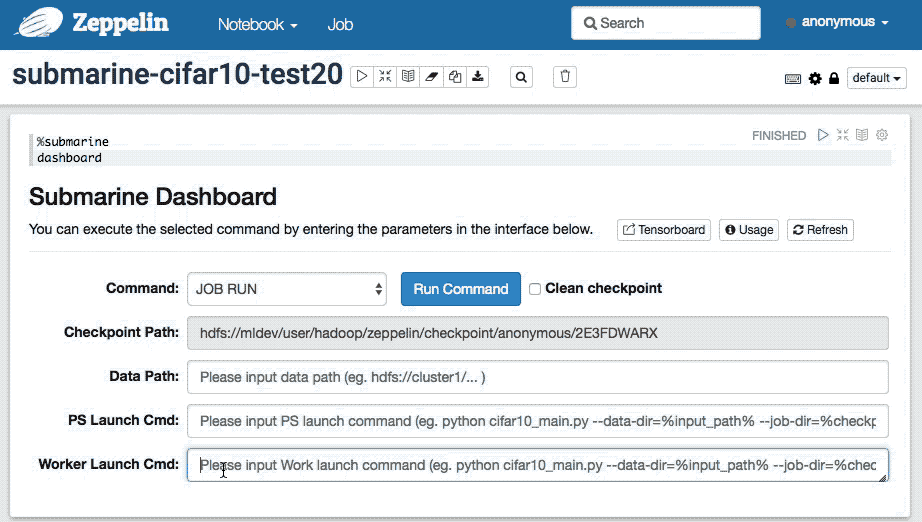
With Submarine Dashboard you can do all the operational control of Submarine, for example:
Usage:Display Submarine's command description to help developers locate problems.
Refresh:Zeppelin will erase all your input in the Dashboard.
Tensorboard:You will be redirected to the Tensorboard WEB system created by Submarine for each user. With Tensorboard you can view the real-time status of the Tensorflow model training in real time.
Command
- JOB RUN:Selecting
JOB RUNwill display the parameter input interface for submitting JOB.
| Name | Description |
|---|---|
| Checkpoint Path/td> | Submarine sets up a separate Checkpoint path for each user's Note for Tensorflow training. Saved the training data for this Note history, Used to train the output of model data, Tensorboard uses the data in this path for model presentation. Users cannot modify it. For example: `hdfs://cluster1/...` , The environment variable name for Checkpoint Path is `%checkpoint_path%`, You can use `%checkpoint_path%` instead of the input value in Data Path in `PS Launch Cmd` and `Worker Launch Cmd`. |
| Input Path | The user specifies the data data directory of the Tensorflow algorithm. Only HDFS-enabled directories are supported. The environment variable name for Data Path is `%input_path%`, You can use `%input_path%` instead of the input value in Data Path in `PS Launch Cmd` and `Worker Launch Cmd`. |
| PS Launch Cmd | Tensorflow Parameter services launch command,例如:`python cifar10_main.py --data-dir=%input_path% --job-dir=%checkpoint_path% --num-gpus=0 ...` |
| Worker Launch Cmd | Tensorflow Worker services launch command,例如:`python cifar10_main.py --data-dir=%input_path% --job-dir=%checkpoint_path% --num-gpus=1 ...` |
JOB STOP
You can choose to execute the
JOB STOPcommand. Stop a Tensorflow model training task that has been submitted and is runningTENSORBOARD START
You can choose to execute the
TENSORBOARD STARTcommand to create your TENSORBOARD Docker Container.TENSORBOARD STOP
You can choose to execute the
TENSORBOARD STOPcommand to stop and destroy your TENSORBOARD Docker Container.
- Run Command:Execute the action command of your choice
- Clean Chechkpoint:Checking this option will clear the data in this Note's Checkpoint Path before each
JOB RUNexecution.
Configuration
Zeppelin Submarine interpreter provides the following properties to customize the Submarine interpreter
| Attribute name | Attribute value | Description |
|---|---|---|
| DOCKER_CONTAINER_TIME_ZONE | Etc/UTC | Set the time zone in the container | |
| DOCKER_HADOOP_HDFS_HOME | /hadoop-3.1-0 | Hadoop path in the following 3 images(SUBMARINE_INTERPRETER_DOCKER_IMAGE、tf.parameter.services.docker.image、tf.worker.services.docker.image) | |
| DOCKER_JAVA_HOME | /opt/java | JAVA path in the following 3 images(SUBMARINE_INTERPRETER_DOCKER_IMAGE、tf.parameter.services.docker.image、tf.worker.services.docker.image) | |
| HADOOP_YARN_SUBMARINE_JAR | Path to the Submarine JAR package in the Hadoop-3.1+ release installed on the Zeppelin server | | |
| INTERPRETER_LAUNCH_MODE | local/yarn | Run the Submarine interpreter instance in local or YARN local mainly for submarine interpreter development and debugging YARN mode for production environment | |
| SUBMARINE_HADOOP_CONF_DIR | Set the HADOOP-CONF path to support multiple Hadoop cluster environments | |
| SUBMARINE_HADOOP_HOME | Hadoop-3.1+ above path installed on the Zeppelin server | |
| SUBMARINE_HADOOP_KEYTAB | Keytab file path for a hadoop cluster with kerberos authentication turned on | |
| SUBMARINE_HADOOP_PRINCIPAL | PRINCIPAL information for the keytab file of the hadoop cluster with kerberos authentication turned on | |
| SUBMARINE_INTERPRETER_DOCKER_IMAGE | At INTERPRETER_LAUNCH_MODE=yarn, Submarine uses this image to create a Zeppelin Submarine interpreter container to create an algorithm development environment for the user. | | |
| docker.container.network | YARN's Docker network name | |
| machinelearing.distributed.enable | Whether to use the model training of the distributed mode JOB RUN submission | |
| shell.command.timeout.millisecs | 60000 | Execute timeout settings for shell commands in the Submarine interpreter container |
| submarine.algorithm.hdfs.path | Save machine-based algorithms developed using Submarine interpreter to HDFS as files | |
| submarine.yarn.queue | root.default | Submarine submits model training YARN queue name |
| tf.checkpoint.path | Tensorflow checkpoint path, Each user will create a user's checkpoint secondary path using the username under this path. Each algorithm submitted by the user will create a checkpoint three-level path using the note id (the user's Tensorboard uses the checkpoint data in this path for visual display) | |
| tf.parameter.services.cpu | Number of CPU cores applied to Tensorflow parameter services when Submarine submits model distributed training | |
| tf.parameter.services.docker.image | Submarine creates a mirror for Tensorflow parameter services when submitting model distributed training | |
| tf.parameter.services.gpu | GPU cores applied to Tensorflow parameter services when Submarine submits model distributed training | |
| tf.parameter.services.memory | 2G | Memory resources requested by Tensorflow parameter services when Submarine submits model distributed training |
| tf.parameter.services.num | Number of Tensorflow parameter services used by Submarine to submit model distributed training | |
| tf.tensorboard.enable | true | Create a separate Tensorboard for each user |
| tf.worker.services.cpu | Submarine submits model resources for Tensorflow worker services when submitting model training | |
| tf.worker.services.docker.image | Submarine creates a mirror for Tensorflow worker services when submitting model distributed training | |
| tf.worker.services.gpu | Submarine submits GPU resources for Tensorflow worker services when submitting model training | |
| tf.worker.services.memory | Submarine submits model resources for Tensorflow worker services when submitting model training | |
| tf.worker.services.num | Number of Tensorflow worker services used by Submarine to submit model distributed training | |
| yarn.webapp.http.address | http://hadoop:8088 | YARN web ui address |
| zeppelin.interpreter.rpc.portRange | 29914 | You need to export this port in the SUBMARINE_INTERPRETER_DOCKER_IMAGE configuration image. RPC communication for Zeppelin Server and Submarine interpreter containers |
| zeppelin.ipython.grpc.message_size | 33554432 | Message size setting for IPython grpc in Submarine interpreter container |
| zeppelin.ipython.launch.timeout | 30000 | IPython execution timeout setting in Submarine interpreter container |
| zeppelin.python | python | Execution path of python in Submarine interpreter container |
| zeppelin.python.maxResult | 10000 | The maximum number of python execution results returned from the Submarine interpreter container |
| zeppelin.python.useIPython | false | IPython is currently not supported and must be false |
| zeppelin.submarine.auth.type | simple/kerberos | Has Hadoop turned on kerberos authentication? |
Docker images
The docker images file is stored in the zeppelin/scripts/docker/submarine directory.
submarine interpreter cpu version
submarine interpreter gpu version
tensorflow 1.10 & hadoop 3.1.2 cpu version
tensorflow 1.10 & hadoop 3.1.2 gpu version
Change Log
0.1.0 (Zeppelin 0.9.0) :
- Support distributed or standolone tensorflow model training.
- Support submarine interpreter running local.
- Support submarine interpreter running YARN.
- Support Docker on YARN-3.3.0, Plan compatible with lower versions of yarn.
Bugs & Contacts
- Submarine interpreter BUG If you encounter a bug for this interpreter, please create a sub JIRA ticket on ZEPPELIN-3856.
- Submarine Running problem If you encounter a problem for Submarine runtime, please create a ISSUE on apache-hadoop-submarine.
- YARN Submarine BUG If you encounter a bug for Yarn Submarine, please create a JIRA ticket on SUBMARINE.
Dependency
- YARN Submarine currently need to run on Hadoop 3.3+
- The hadoop version of the hadoop submarine team git repository is periodically submitted to the code repository of the hadoop.
- The version of the git repository for the hadoop submarine team will be faster than the hadoop version release cycle.
- You can use the hadoop version of the hadoop submarine team git repository.
- Submarine runtime environment you can use Submarine-installer https://github.com/apache/submarine, Deploy Docker and network environments.
More
Hadoop Submarine Project: https://submarine.apache.org/ Youtube Submarine Channel: https://www.youtube.com/channel/UC4JBt8Y8VJ0BW0IM9YpdCyQ