Apache Zeppelin on CDH
1. Import Cloudera QuickStart Docker image
Cloudera has officially provided CDH Docker Hub in their own container. Please check this guide page for more information.
You can import the Docker image by pulling it from Cloudera Docker Hub.
docker pull cloudera/quickstart:latest
2. Run docker
docker run -it \
-p 80:80 \
-p 4040:4040 \
-p 8020:8020 \
-p 8022:8022 \
-p 8030:8030 \
-p 8032:8032 \
-p 8033:8033 \
-p 8040:8040 \
-p 8042:8042 \
-p 8088:8088 \
-p 8480:8480 \
-p 8485:8485 \
-p 8888:8888 \
-p 9083:9083 \
-p 10020:10020 \
-p 10033:10033 \
-p 18088:18088 \
-p 19888:19888 \
-p 25000:25000 \
-p 25010:25010 \
-p 25020:25020 \
-p 50010:50010 \
-p 50020:50020 \
-p 50070:50070 \
-p 50075:50075 \
-h quickstart.cloudera --privileged=true \
agitated_payne_backup /usr/bin/docker-quickstart;
3. Verify running CDH
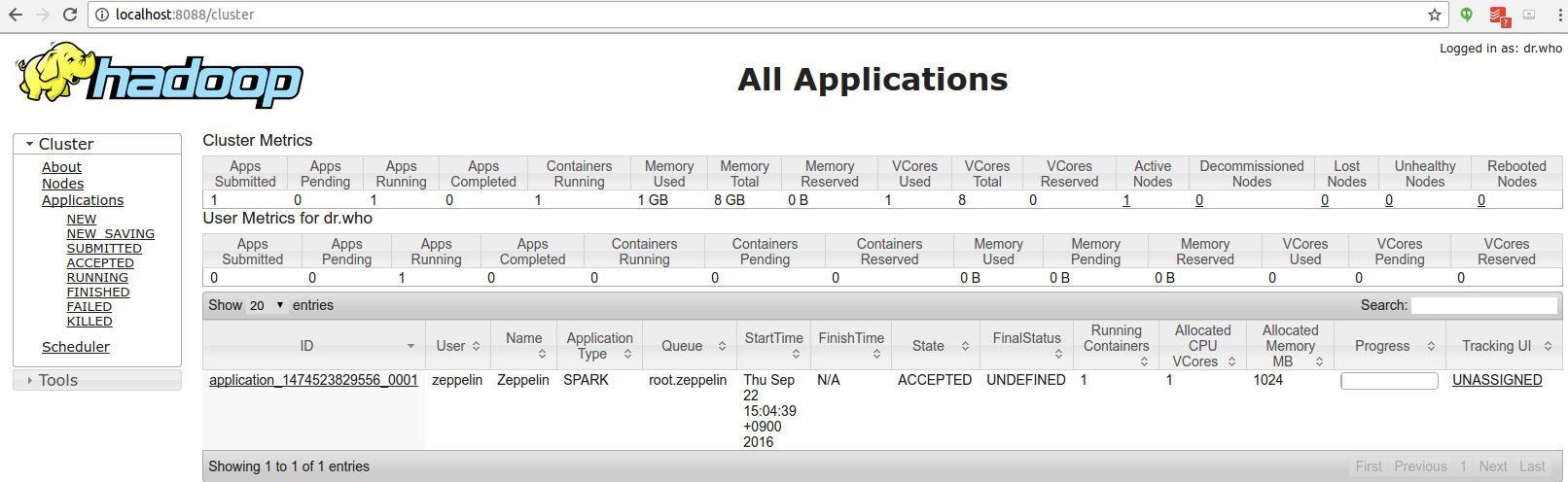
To verify the application is running well, check the web UI for HDFS on http://<hostname>:50070/ and YARN on http://<hostname>:8088/cluster.
4. Configure Spark interpreter in Zeppelin
Set following configurations to conf/zeppelin-env.sh.
export HADOOP_CONF_DIR=[your_hadoop_conf_path]
export SPARK_HOME=[your_spark_home_path]
HADOOP_CONF_DIR(Hadoop configuration path) is defined in /scripts/docker/spark-cluster-managers/cdh/hdfs_conf.
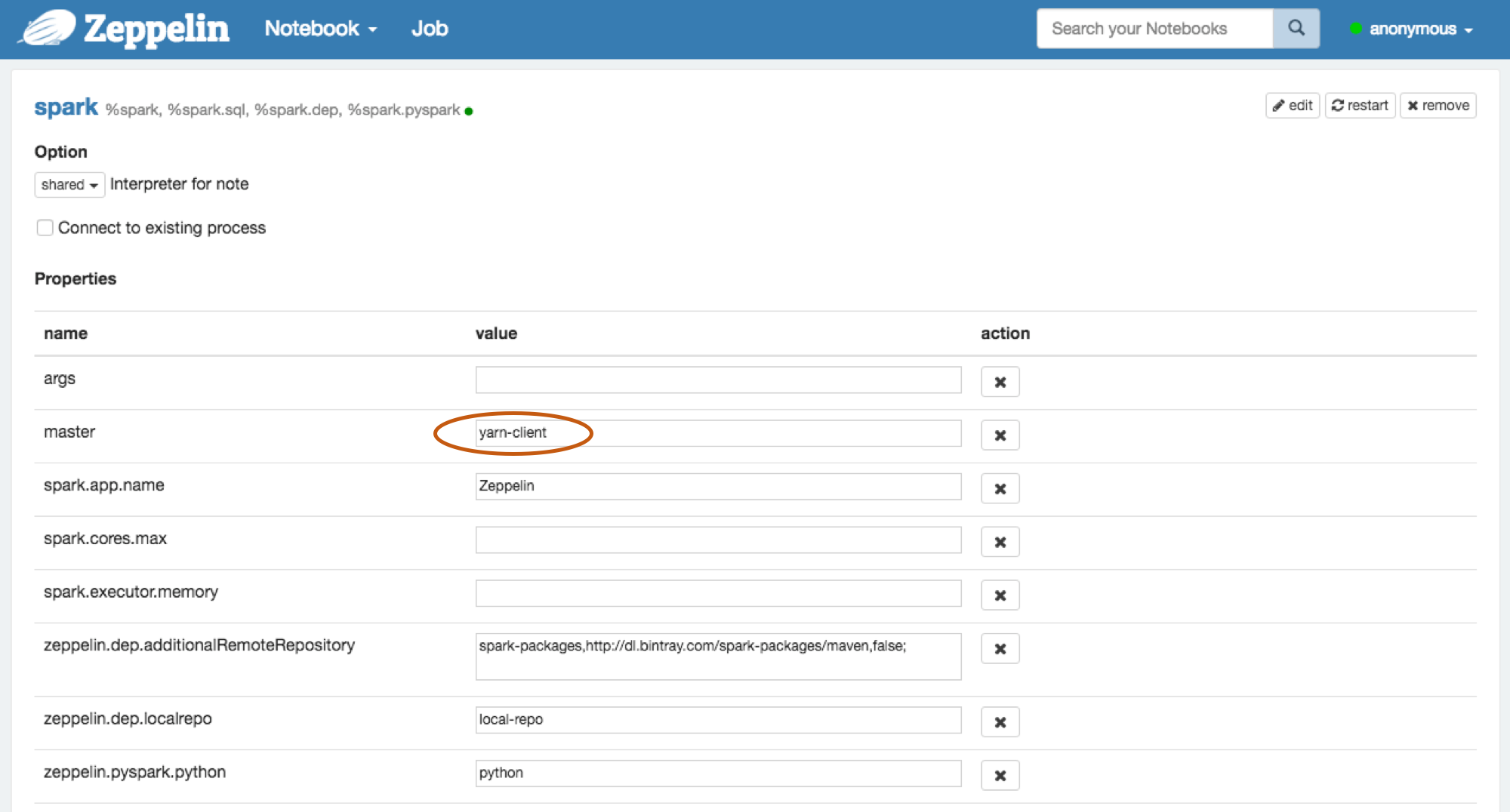
Don't forget to set Spark spark.master as yarn-client in Zeppelin Interpreters setting page like below.
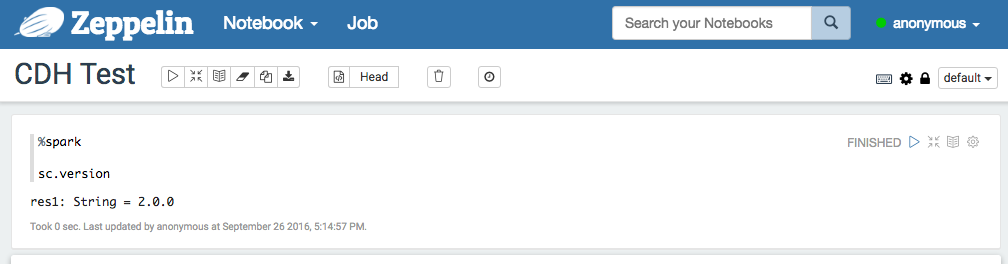
5. Run Zeppelin with Spark interpreter
After running a single paragraph with Spark interpreter in Zeppelin,
browse http://<hostname>:8088/cluster/apps to check Zeppelin application is running well or not.