Zeppelin-Context
The zeppelin-context is a system-wide container for common utility functions and user-specific data. It implements functions for data input, data display, etc. that are often needed but are not uniformly available in all interpreters. Its single per-user instance is accessible across all of the user's notebooks and cells, enabling data exchange between cells - even in different notebooks. But the way in which the zeppelin-context is used, and the functionality available differs depending on whether or not the associated interpreter is based on a programming language. Details of how the zeppelin-context is used for different purposes and in different environments is described below.
Usage in Programming Language Cells
In many programming-language interpreters (e.g. Apache Spark, Python, R) the zeppelin-context is available
as a predefined variable z that can be used by directly invoking its methods.
The methods available on the z object are described below.
Other interpreters based on programming languages. also provide the predefined variable z.
Exploring Spark DataFrames
In the Apache Spark interpreter, the zeppelin-context provides a show method, which,
using Zeppelin's table feature, can be used to nicely display a Spark DataFrame:
df = spark.read.csv('/path/to/csv')
z.show(df)
This display functionality using the show method is planned to be extended uniformly to
other interpreters that can access the z object (Flink already support to show table too).
Object Exchange
ZeppelinContext extends map and it's shared between the Apache Spark and Python environments.
So you can put some objects using Scala (in an Apache Spark cell) and read it from Python, and vice versa.
// Put/Get object from scala
%spark
val myObject = "hello"
z.put("objName", myObject)
z.get("objName")
# Put/Get object from python
%spark.pyspark
val myObject = "hello"
z.put("objName", myObject)
myObject = z.get("objName")
# df is Python pandas DataFrame
# "table_name" must be table type. Currently only sql interpreter (%spark.sql or %jdbc) result is supported.
df = z.getAsDataFrame("table_name")
# Get/Put object from R
%spark.r
z.put("objName", myObject)
myObject <- z.get("objName")
# df is R DataFrame
# "table_name" must be table type. Currently only sql interpreter (%spark.sql or %jdbc) result is supported.
df <- z.getAsDataFrame("table_name")
Currently, there're two types of data could be shared across interpreters:
- String Data
- Table Data
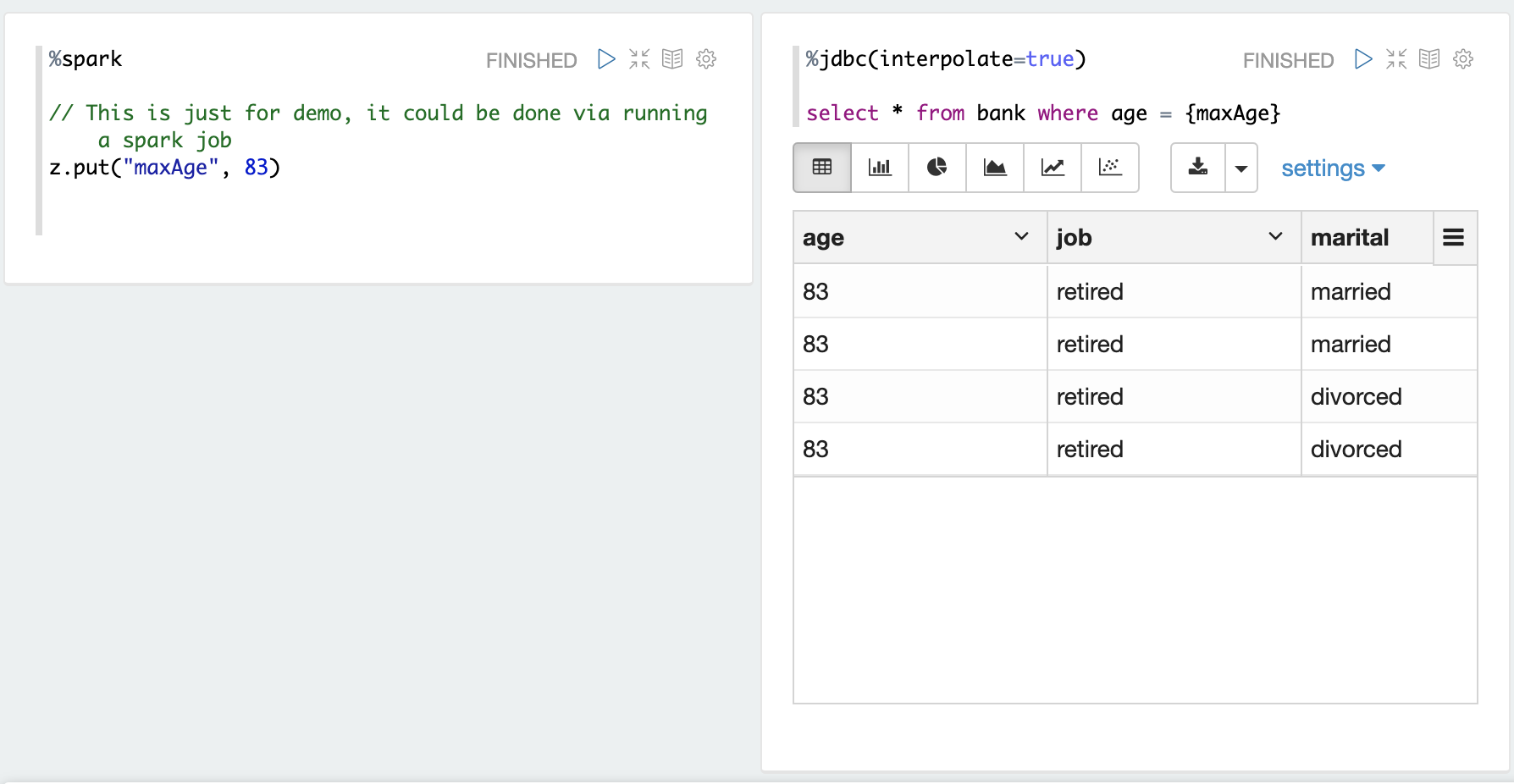
Share String Object
Here's one example we share one String object maxAge between Spark interpreter and jdbc interpreter.
%spark
z.put("maxAge", 83)
%jdbc(interpolate=true)
select * from bank where age = {maxAge}
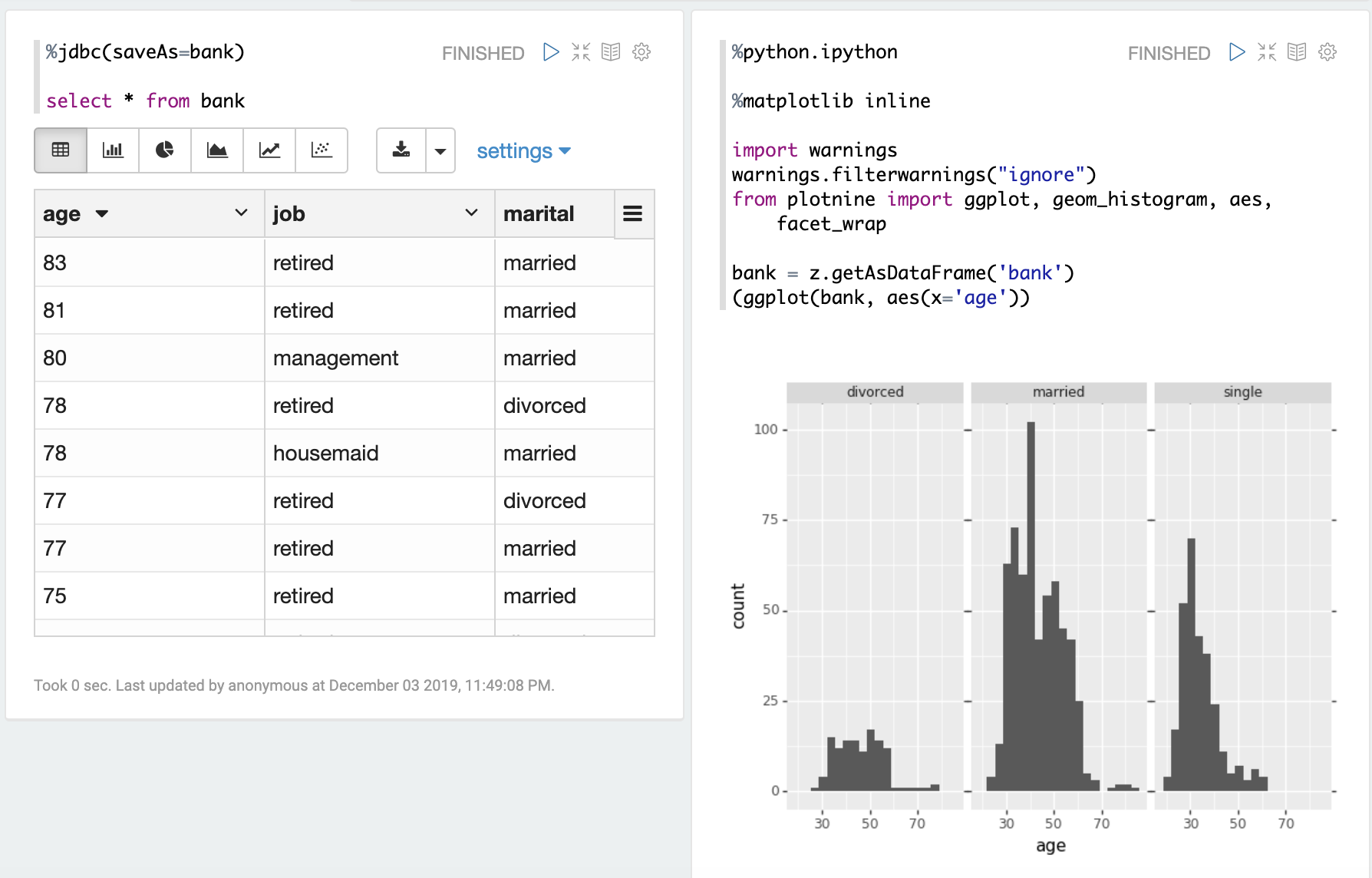
Share Table Object
Here's one example we share one Table object between jdbc interpreter and python interpreter.
%jdbc(saveAs=bank)
select * from bank
%python.ipython
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
from plotnine import ggplot, geom_histogram, aes, facet_wrap
bank = z.getAsDataFrame('bank')
(ggplot(bank, aes(x='age'))
Form Creation
ZeppelinContext provides functions for creating forms.
In Scala and Python environments, you can create forms programmatically.
%spark
/* Create text input form */
z.input("input_1")
/* Create text input form with default value */
z.input("input_2", "defaultValue")
/* Create select form */
z.select("select_1", Seq(("option1", "option1DisplayName"),
("option2", "option2DisplayName")))
/* Create select form with default value*/
z.select("select_2", "option1", Seq(("option1", "option1DisplayName"),
("option2", "option2DisplayName")))
%spark.pyspark
# Create text input form
z.input("input_1")
# Create text input form with default value
z.input("input_2", "defaultValue")
# Create select form
z.select("select_1", [("option1", "option1DisplayName"),
("option2", "option2DisplayName")])
# Create select form with default value
z.select("select_2", [("option1", "option1DisplayName"),
("option2", "option2DisplayName")], "option1")
Patterns of the form ${ ... } are used to dynamically create additional HTML elements for requesting user input (that replaces the corresponding pattern in the paragraph text). Currently only text, select with options, and checkbox are supported.
Dynamic forms are described in detail here: Dynamic Form.
In sql environment, you can create dynamic form in simple template.
%spark.sql
select * from ${table=defaultTableName} where text like '%${search}%'
To learn more about dynamic form, checkout Dynamic Form.
Usage with Embedded Commands
In certain interpreters (see table below) zeppelin-context features may be invoked by embedding command strings into the paragraph text. Such embedded command strings are used to invoke dynamic-forms and object-interpolation as described below.
| Interpreters that use Embedded Commands |
|---|
| spark.sql (*), bigquery, cassandra, elasticsearch, file, hbase, jdbc (*), livy, markdown, neo4j, python, shell (*), zengine |
Dynamic forms are available in all of the interpreters in the table above, but object interpolation is only available in a small, but growing, list of interpreters (marked with an asterisk in the table above). Both these zeppelin-context features are described below.
Object Interpolation
Some interpreters can interpolate object values from z into the paragraph text by using the
{variable-name} syntax. The value of any object previously put into z can be
interpolated into a paragraph text by using such a pattern containing the object's name.
The following example shows one use of this facility:
In Scala cell:
%spark
z.put("minAge", 35)
In later SQL cell:
%spark.sql
select * from members where age >= {minAge}
The interpolation of a {var-name} pattern is performed only when z contains an object with the specified name.
But the pattern is left unchanged if the named object does not exist in z.
Further, all {var-name} patterns within the paragraph text must be translatable for any interpolation to occur --
translation of only some of the patterns in a paragraph text is never done.
In some situations, it is necessary to use { and } characters in a paragraph text without invoking the object interpolation mechanism. For these cases an escaping mechanism is available -- doubled braces should be used. The following example shows the use of for passing a regular expression containing just { and } into the paragraph text.
%spark.sql
select * from members where name rlike '[aeiou]{{3}}'
To summarize, patterns of the form {var-name} within the paragraph text will be interpolated only if a predefined
object of the specified name exists. Additionally, all such patterns within the paragraph text should also
be translatable for any interpolation to occur. Patterns of the form {{any-text}} are translated into {any-text}.
These translations are performed only when all occurrences of {, }, {{, and }} in the paragraph text conform
to one of the two forms described above. Paragraph text containing { and/or } characters used in any other way
(than {var-name} and {{any-text}} ) is used as-is without any changes.
No error is flagged in any case. This behavior is identical to the implementation of a similar feature in
Jupyter's shell invocation using the ! magic command.
This feature is disabled by default, and must be explicitly turned on for each interpreter independently
by setting the value of an interpreter-specific property to true.
Consult the Configuration section of each interpreter's documentation
to find out if object interpolation is implemented, and the name of the parameter that must be set to true to
enable the feature. The name of the parameter used to enable this feature is different for each interpreter.
For example, the SparkSQL and Shell interpreters use the parameter names zeppelin.spark.sql.interpolation and
zeppelin.shell.interpolation respectively.
At present only the SparkSQL, JDBC, and Shell interpreters support object interpolation.
Interpreter-Specific Functions
Some interpreters use a subclass of BaseZepplinContext augmented with interpreter-specific functions.
Such interpreter-specific functions are described within each interpreter's documentation.