Python 2 & 3 Interpreter for Apache Zeppelin
Overview
Zeppelin supports python language which is very popular in data analytics and machine learning.
| Name | Class | Description |
|---|---|---|
| %python | PythonInterpreter | Vanilla python interpreter, with least dependencies, only python environment installed is required, %python will use IPython if its prerequisites are met |
| %python.ipython | IPythonInterpreter | Provide more fancy python runtime via IPython, almost the same experience like Jupyter. It requires more things, but is the recommended interpreter for using python in Zeppelin, see below for more details |
| %python.sql | PythonInterpreterPandasSql | Provide sql capability to query data in Pandas DataFrame via pandasql, it can access dataframes in %python |
Main Features
| Feature | Description |
|---|---|
| Support vanilla Python and IPython | Vanilla Python only requires python install, IPython provides almost the same user experience like Jupyter, like inline plotting, code completion, magic methods and etc. |
| Built-in ZeppelinContext Support | You can use ZeppelinContext to visualize pandas dataframe |
| Support SQL on Pandas dataframe | You can use Sql to query dataframe which is defined in Python |
| Run Python in yarn cluster with customized Python runtime | You can run Python in yarn cluster with customized Python runtime without affecting each other |
Play Python in Zeppelin docker
For beginner, we would suggest you to play Python in Zeppelin docker first.
In the Zeppelin docker image, we have already installed
miniconda and lots of useful python libraries
including IPython's prerequisites, so %python would use IPython.
Without any extra configuration, you can run most of tutorial notes under folder Python Tutorial directly.
docker run -u $(id -u) -p 8080:8080 --rm --name zeppelin apache/zeppelin:0.10.0
After running the above command, you can open http://localhost:8080 to play Python in Zeppelin.
Configuration
| Property | Default | Description |
|---|---|---|
| zeppelin.python | python | Path of the installed Python binary (could be python2 or python3).
You should set this property explicitly if python is not in your $PATH(example: /usr/bin/python).
|
| zeppelin.python.maxResult | 1000 | Max number of dataframe rows to display. |
| zeppelin.python.useIPython | true | When this property is true, %python would be delegated to %python.ipython if IPython is available, otherwise
IPython is only used in %python.ipython.
|
| zeppelin.yarn.dist.archives | Used for ipython in yarn mode. It is a general zeppelin interpreter configuration, not python specific. For Python interpreter it is used to specify the conda env archive file which could be on local filesystem or on hadoop compatible file system. | |
| zeppelin.interpreter.conda.env.name | Used for ipython in yarn mode. conda environment name, aka the folder name in the working directory of interpreter yarn container. |
Vanilla Python Interpreter (%python)
The vanilla python interpreter provides basic python interpreter feature, only python installed is required.
Matplotlib integration
The vanilla python interpreter can display matplotlib figures inline automatically using the matplotlib:
%python
import matplotlib.pyplot as plt
plt.plot([1, 2, 3])
The output of this command will by default be converted to HTML by implicitly making use of the %html magic. Additional configuration can be achieved using the builtin z.configure_mpl() method. For example,
z.configure_mpl(width=400, height=300, fmt='svg')
plt.plot([1, 2, 3])
Will produce a 400x300 image in SVG format, which by default are normally 600x400 and PNG respectively.
In the future, another option called angular can be used to make it possible to update a plot produced from one paragraph directly from another
(the output will be %angular instead of %html). However, this feature is already available in the pyspark interpreter.
More details can be found in the included "Zeppelin Tutorial: Python - matplotlib basic" tutorial notebook.
If Zeppelin cannot find the matplotlib backend files (which should usually be found in $ZEPPELIN_HOME/interpreter/lib/python) in your PYTHONPATH,
then the backend will automatically be set to agg, and the (otherwise deprecated) instructions below can be used for more limited inline plotting.
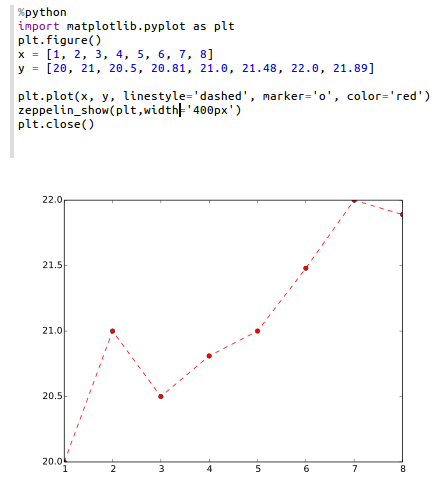
If you are unable to load the inline backend, use z.show(plt):
%python
import matplotlib.pyplot as plt
plt.figure()
(.. ..)
z.show(plt)
plt.close()
The z.show() function can take optional parameters to adapt graph dimensions (width and height) as well as output format (png or optionally svg).
%python
z.show(plt, width='50px')
z.show(plt, height='150px', fmt='svg')
IPython Interpreter (%python.ipython) (recommended)
IPython is more powerful than the vanilla python interpreter with extra functionality. This is what we recommend you to use instead of vanilla python interpreter. You can use IPython with Python2 or Python3 which depends on which python you set in zeppelin.python.
Prerequisites
- For non-anaconda environment, You need to install the following packages
pip install jupyter
pip install grpcio
pip install protobuf
- For anaconda environment (
zeppelin.pythonpoints to the python under anaconda)
pip install grpcio
pip install protobuf
Zeppelin will check the above prerequisites when using %python, if IPython prerequisites are met, %python would use IPython interpreter,
otherwise it would use vanilla Python interpreter in %python.
In addition to all the basic functions of the vanilla python interpreter, you can use all the IPython advanced features as you use it in Jupyter Notebook.
Take a look at tutorial note Python Tutorial/1. IPython Basic and Python Tutorial/2. IPython Visualization Tutorial for how to use IPython in Zeppelin.
Use IPython magic
%python.ipython
#python help
range?
#timeit
%timeit range(100)
Use matplotlib
%python.ipython
%matplotlib inline
import matplotlib.pyplot as plt
print("hello world")
data=[1,2,3,4]
plt.figure()
plt.plot(data)
Run shell command
%python.ipython
!pip install pandas
Colored text output
More types of visualization
e.g. You can use hvplot in the same way as in Jupyter, Take a look at tutorial note Python Tutorial/2. IPython Visualization Tutorial for more visualization examples.

Better code completion
Type tab can give you all the completion candidates just like in Jupyter.
Pandas Integration
Apache Zeppelin Table Display System provides built-in data visualization capabilities.
Python interpreter leverages it to visualize Pandas DataFrames via z.show() API.
For example:
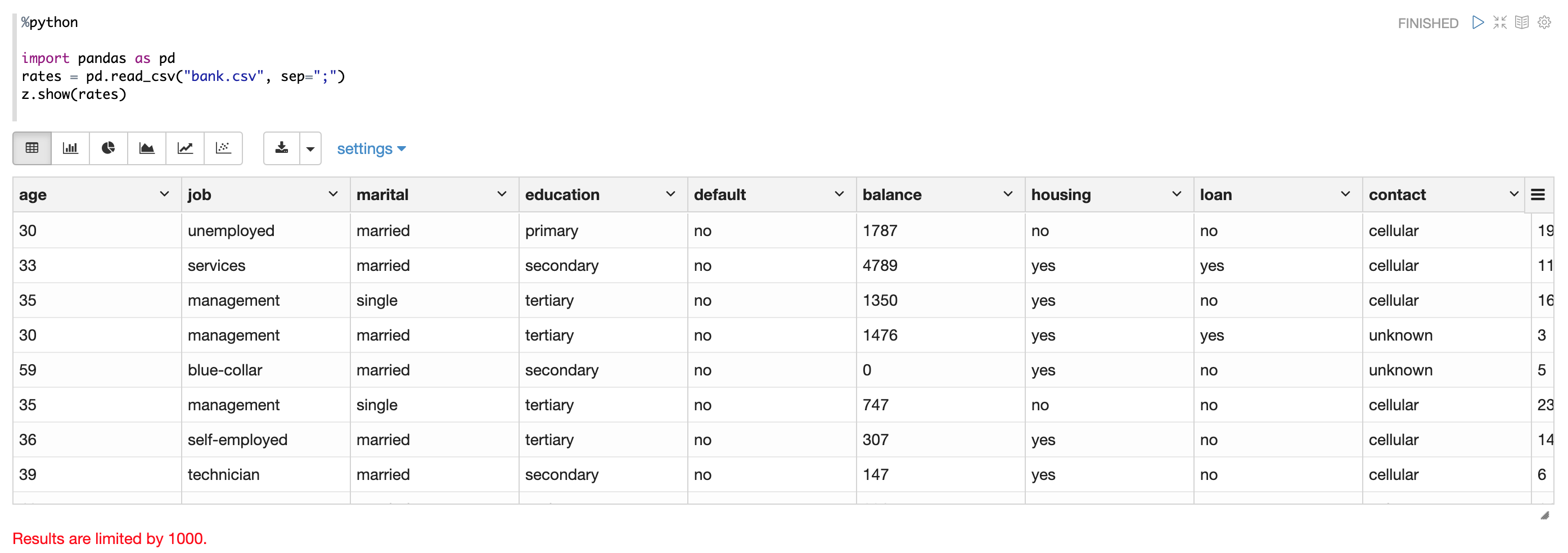
By default, z.show only display 1000 rows, you can configure zeppelin.python.maxResult to adjust the max number of rows.
SQL over Pandas DataFrames
There is a convenience %python.sql interpreter that matches Apache Spark experience in Zeppelin and
enables usage of SQL language to query Pandas DataFrames and
visualization of results through built-in Table Display System.
%python.sql can access dataframes defined in %python.
Prerequisites
- Pandas
pip install pandas - PandaSQL
pip install -U pandasql
Here's one example:
first paragraph
%python import pandas as pd rates = pd.read_csv("bank.csv", sep=";")next paragraph
%python.sql SELECT * FROM rates WHERE age < 40
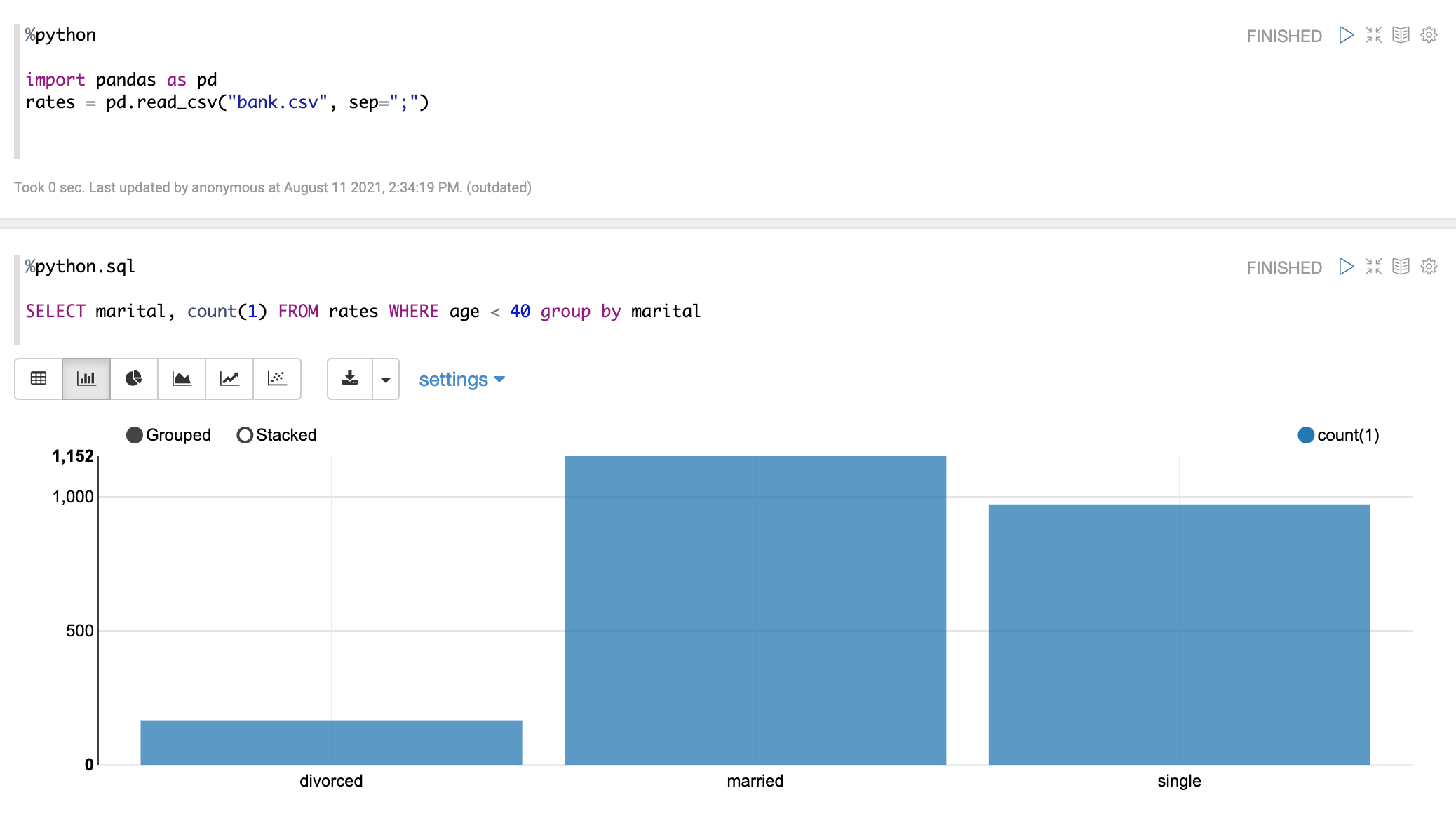
Using Zeppelin Dynamic Forms
You can leverage Zeppelin Dynamic Form inside your Python code.
Example :
%python
### Input form
print(z.input("f1","defaultValue"))
### Select form
print(z.select("f2",[("o1","1"),("o2","2")],"o1"))
### Checkbox form
print("".join(z.checkbox("f3", [("o1","1"), ("o2","2")],["o1"])))
ZeppelinContext API
Python interpreter create a variable z which represent ZeppelinContext for you. User can use it to do more fancy and complex things in Zeppelin.
| API | Description |
|---|---|
| z.put(key, value) | Put object value with identifier key to distributed resource pool of Zeppelin,
so that it can be used by other interpreters |
| z.get(key) | Get object with identifier key from distributed resource pool of Zeppelin |
| z.remove(key) | Remove object with identifier key from distributed resource pool of Zeppelin |
| z.getAsDataFrame(key) | Get object with identifier key from distributed resource pool of Zeppelin and converted into pandas dataframe.
The object in the distributed resource pool must be table type, e.g. jdbc interpreter result.
|
| z.angular(name, noteId = None, paragraphId = None) | Get the angular object with identifier name |
| z.angularBind(name, value, noteId = None, paragraphId = None) | Bind value to angular object with identifier name |
| z.angularUnbind(name, noteId = None) | Unbind value from angular object with identifier name |
| z.show(p) | Show python object p in Zeppelin, if it is pandas dataframe, it would be displayed in Zeppelin's table format,
others will be converted to string |
| z.textbox(name, defaultValue="") | Create dynamic form Textbox name with defaultValue |
| z.select(name, options, defaultValue="") | Create dynamic form Select name with options and defaultValue. options should be a list of Tuple(first element is key,
the second element is the displayed value) e.g. z.select("f2",[("o1","1"),("o2","2")],"o1") |
| z.checkbox(name, options, defaultChecked=[]) | Create dynamic form Checkbox `name` with options and defaultChecked. options should be a list of Tuple(first element is key,
the second element is the displayed value) e.g. z.checkbox("f3", [("o1","1"), ("o2","2")],["o1"]) |
| z.noteTextbox(name, defaultValue="") | Create note level dynamic form Textbox |
| z.noteSelect(name, options, defaultValue="") | Create note level dynamic form Select |
| z.noteCheckbox(name, options, defaultChecked=[]) | Create note level dynamic form Checkbox |
| z.run(paragraphId) | Run paragraph |
| z.run(noteId, paragraphId) | Run paragraph |
| z.runNote(noteId) | Run the whole note |
Run Python interpreter in yarn cluster
Zeppelin supports to run interpreter in yarn cluster which means the python interpreter can run in a yarn container. This can achieve better multi-tenant for python interpreter especially when you already have a hadoop yarn cluster.
But there's one critical problem to run python in yarn cluster: how to manage the python environment in yarn container. Because hadoop yarn cluster is a distributed cluster environment which is composed of many nodes, and your python interpreter can start in any node. It is not practical to manage python environment in each node beforehand.
So in order to run python in yarn cluster, we would suggest you to use conda to manage your python environment, and Zeppelin can ship your conda environment to yarn container, so that each python interpreter can have its own python environment without affecting each other.
Python interpreter in yarn cluster only works for IPython, so make sure IPython's prerequisites are met. So make sure including the following packages in Step 1.
- python
- jupyter
- grpcio
- protobuf
Step 1
We would suggest you to use conda-pack to create archive of conda environment, and ship it to yarn container. Otherwise python interpreter will use the python executable file in PATH of yarn container.
Here's one example of yaml file which could be used to create a conda environment with python 3 and some useful python libraries.
- Create yaml file for conda environment, write the following content into file
python_3_env.yml
name: python_3_env
channels:
- conda-forge
- defaults
dependencies:
- python=3.9
- jupyter
- grpcio
- protobuf
- pycodestyle
- numpy
- pandas
- scipy
- pandasql
- panel
- pyyaml
- seaborn
- plotnine
- hvplot
- intake
- intake-parquet
- intake-xarray
- altair
- vega_datasets
- pyarrow
conda env create -f python_3_env.yml
mamba env create -f python_3_env
- Pack the conda environment using
conda
conda pack -n python_3_env
Step 2
Specify the following properties to enable yarn mode for python interpreter.
%python.conf
zeppelin.interpreter.launcher yarn
zeppelin.yarn.dist.archives /home/hadoop/python_3_env.tar.gz#environment
zeppelin.interpreter.conda.env.name environment
Setting zeppelin.interpreter.launcher as yarn will launch python interpreter in yarn cluster.
zeppelin.yarn.dist.archives is the python conda environment tar which is created in step 1.
This tar will be shipped to yarn container and untar in the working directory of yarn container.
environment in /home/hadoop/python_3.tar.gz#environment is the folder name after untar.
This folder name should be the same as zeppelin.interpreter.conda.env.name. Usually we name it as environment here.
Python environments (used for vanilla python interpreter in non-yarn mode)
Default
By default, PythonInterpreter will use python command defined in zeppelin.python property to run python process.
The interpreter can use all modules already installed (with pip, easy_install...)
Conda
Conda is an package management system and environment management system for python.
%python.conda interpreter lets you change between environments.
Usage
get the Conda Information:
%python.conda infolist the Conda environments:
%python.conda env listcreate a conda enviornment:
%python.conda create --name [ENV NAME]activate an environment (python interpreter will be restarted):
%python.conda activate [ENV NAME]deactivate
%python.conda deactivateget installed package list inside the current environment
%python.conda listinstall package
%python.conda install [PACKAGE NAME]uninstall package
%python.conda uninstall [PACKAGE NAME]
Docker
%python.docker interpreter allows PythonInterpreter creates python process in a specified docker container.
Usage
activate an environment
%python.docker activate [Repository] %python.docker activate [Repository:Tag] %python.docker activate [Image Id]deactivate
%python.docker deactivate
Here is an example
# activate latest tensorflow image as a python environment
%python.docker activate gcr.io/tensorflow/tensorflow:latest
Community
Join our community to discuss with others.