Flink interpreter for Apache Zeppelin
Overview
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
In Zeppelin 0.9, we refactor the Flink interpreter in Zeppelin to support the latest version of Flink. Currently, only Flink 1.15+ is supported, old versions of flink won't work. Apache Flink is supported in Zeppelin with the Flink interpreter group which consists of the five interpreters listed below.
| Name | Class | Description |
|---|---|---|
| %flink | FlinkInterpreter | Creates ExecutionEnvironment/StreamExecutionEnvironment/BatchTableEnvironment/StreamTableEnvironment and provides a Scala environment |
| %flink.pyflink | PyFlinkInterpreter | Provides a python environment |
| %flink.ipyflink | IPyFlinkInterpreter | Provides an ipython environment |
| %flink.ssql | FlinkStreamSqlInterpreter | Provides a stream sql environment |
| %flink.bsql | FlinkBatchSqlInterpreter | Provides a batch sql environment |
Main Features
| Feature | Description |
|---|---|
| Support multiple versions of Flink | You can run different versions of Flink in one Zeppelin instance |
| Support multiple languages | Scala, Python, SQL are supported, besides that you can also collaborate across languages, e.g. you can write Scala UDF and use it in PyFlink |
| Support multiple execution modes | Local | Remote | Yarn | Yarn Application |
| Support Hive | Hive catalog is supported |
| Interactive development | Interactive development user experience increase your productivity |
| Enhancement on Flink SQL | * Support both streaming sql and batch sql in one notebook * Support sql comment (single line comment/multiple line comment) * Support advanced configuration (jobName, parallelism) * Support multiple insert statements |
Multi-tenancy | Multiple user can work in one Zeppelin instance without affecting each other. | Rest API Support | You can not only submit Flink job via Zeppelin notebook UI, but also can do that via its rest api (You can use Zeppelin as Flink job server). |
Play Flink in Zeppelin docker
For beginner, we would suggest you to play Flink in Zeppelin docker.
First you need to download Flink, because there's no Flink binary distribution shipped with Zeppelin.
e.g. Here we download Flink 1.12.2 to/mnt/disk1/flink-1.12.2,
and we mount it to Zeppelin docker container and run the following command to start Zeppelin docker.
docker run -u $(id -u) -p 8080:8080 -p 8081:8081 --rm -v /mnt/disk1/flink-1.12.2:/opt/flink -e FLINK_HOME=/opt/flink --name zeppelin apache/zeppelin:0.10.0
After running the above command, you can open http://localhost:8080 to play Flink in Zeppelin. We only verify the flink local mode in Zeppelin docker, other modes may not due to network issues.
-p 8081:8081 is to expose Flink web ui, so that you can access Flink web ui via http://localhost:8081.
Here's screenshot of running note Flink Tutorial/5. Streaming Data Analytics
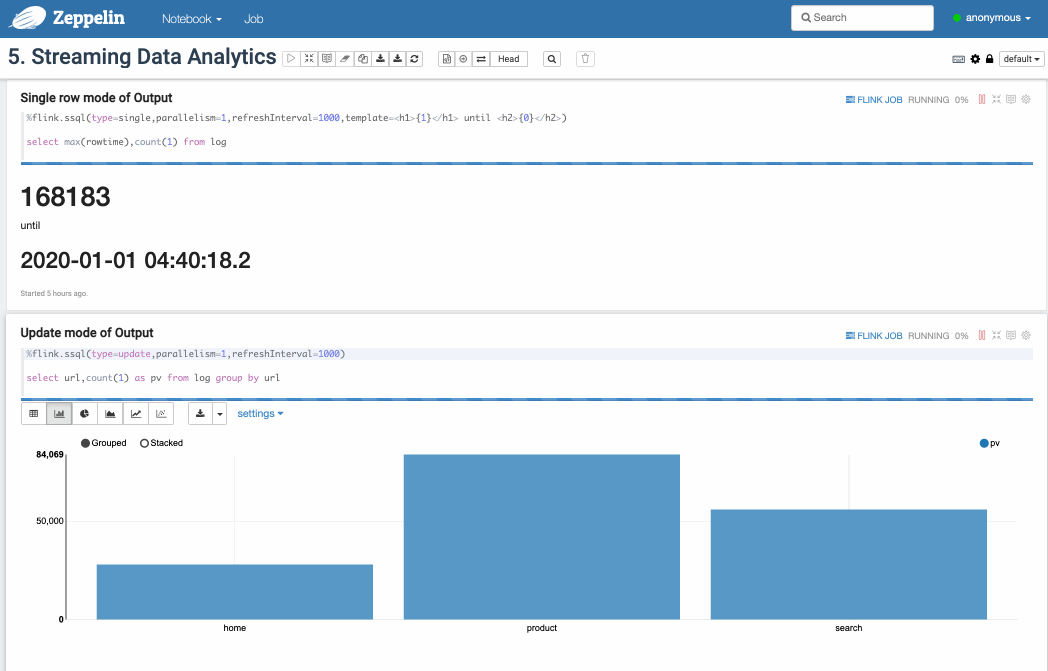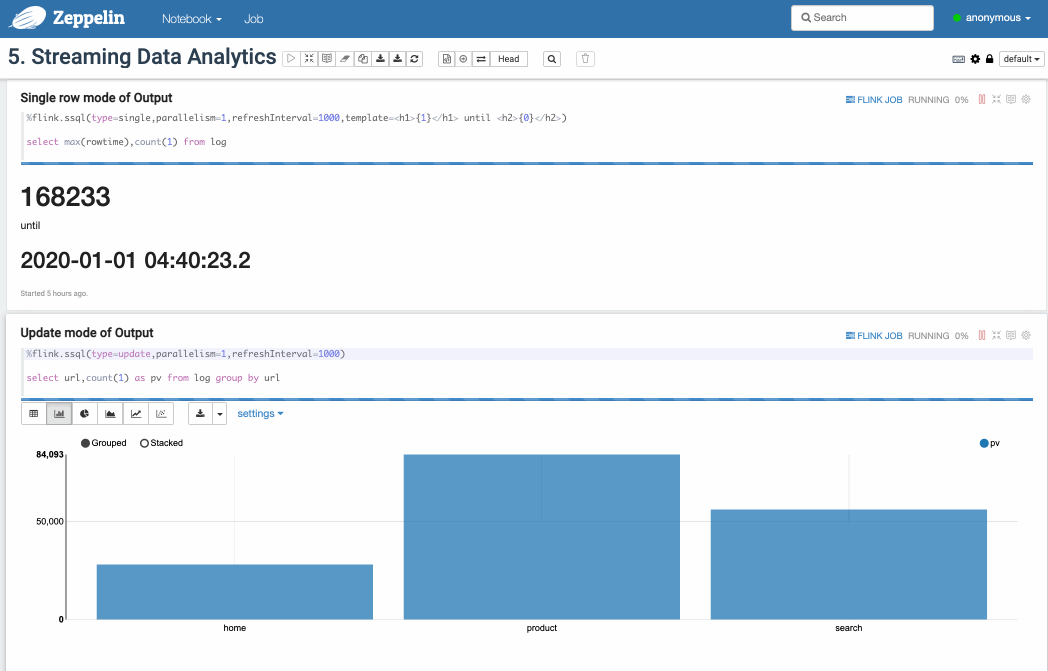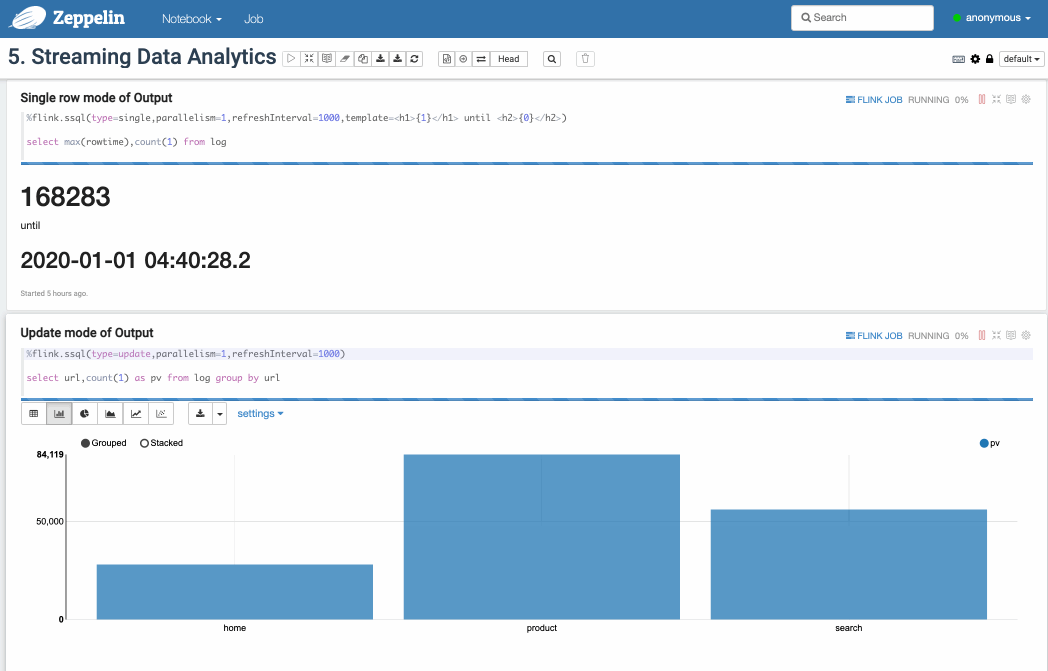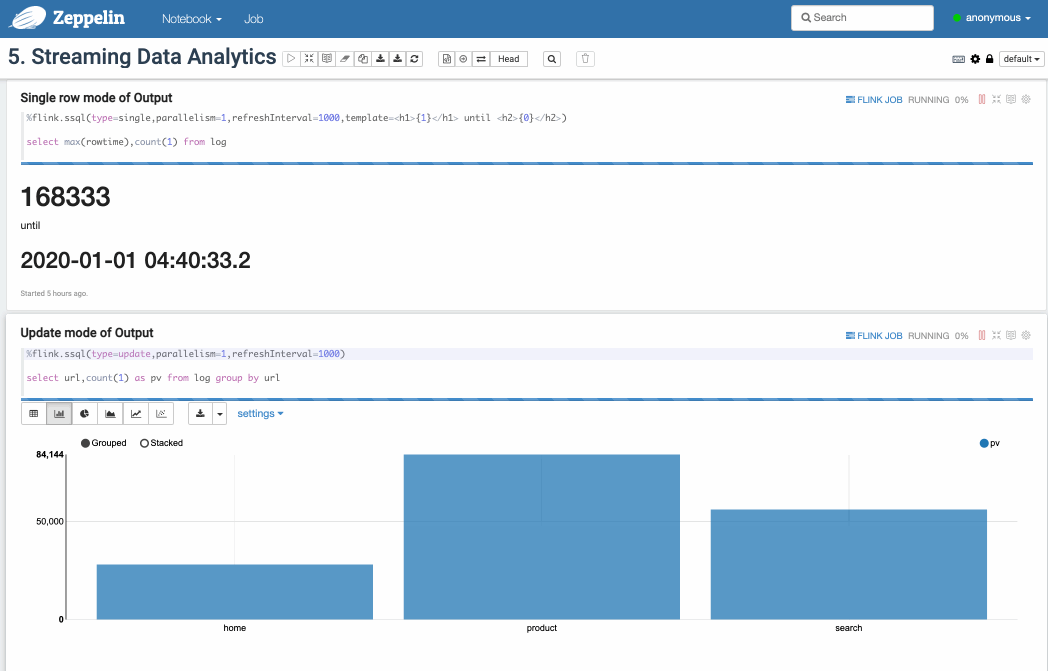
You can also mount notebook folder to replace the built-in zeppelin tutorial notebook. e.g. Here's a repo of Flink sql cookbook on Zeppelin: https://github.com/zjffdu/flink-sql-cookbook-on-zeppelin/
You can clone this repo and mount it to docker,
docker run -u $(id -u) -p 8080:8080 --rm -v /mnt/disk1/flink-sql-cookbook-on-zeppelin:/notebook -v /mnt/disk1/flink-1.12.2:/opt/flink -e FLINK_HOME=/opt/flink -e ZEPPELIN_NOTEBOOK_DIR='/notebook' --name zeppelin apache/zeppelin:0.10.0
Prerequisites
Download Flink 1.15 or afterwards (Only Scala 2.12 is supported)
Version-specific notes for Flink
Flink 1.15 is scala free and has changed its binary distribution, the following extra steps is required. * Move FLINKHOME/opt/flink-table-planner2.12-1.15.0.jar to FLINKHOME/lib * Move FLINKHOME/lib/flink-table-planner-loader-1.15.0.jar to FLINKHOME/opt * Download flink-table-api-scala-bridge2.12-1.15.0.jar and flink-table-api-scala2.12-1.15.0.jar to FLINKHOME/lib
Flink 1.16 introduces new ClientResourceManager for sql client, you need to move FLINK_HOME/opt/flink-sql-client-1.16.0.jar to FLINK_HOME/lib
Flink on Zeppelin Architecture
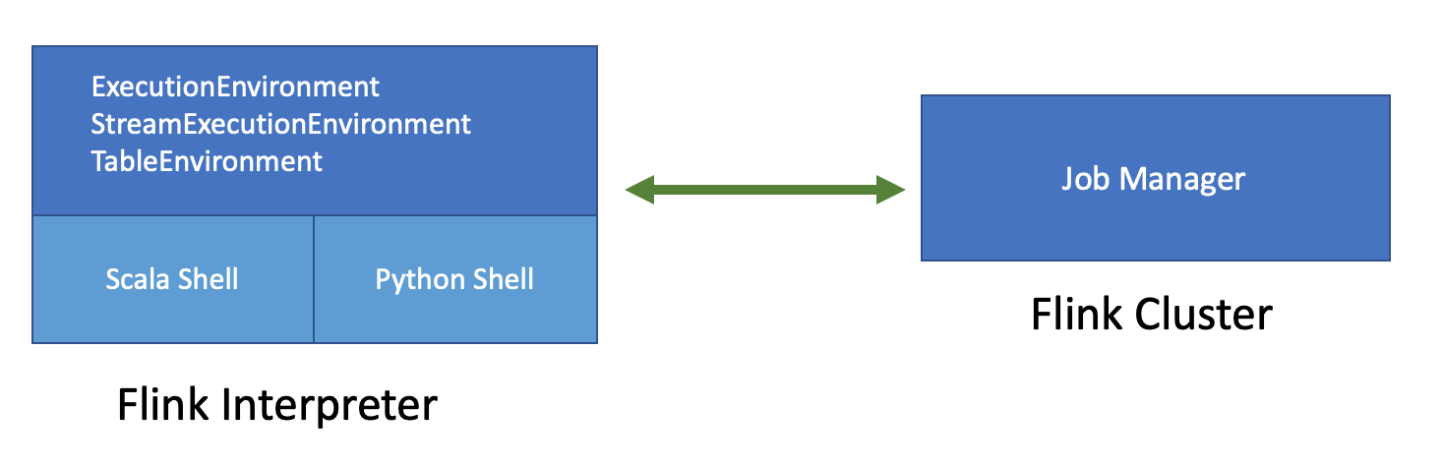
The above diagram is the architecture of Flink on Zeppelin. Flink interpreter on the left side is actually a Flink client which is responsible for compiling and managing Flink job lifecycle, such as submit, cancel job, monitoring job progress and so on. The Flink cluster on the right side is the place where executing Flink job. It could be a MiniCluster (local mode), Standalone cluster (remote mode), Yarn session cluster (yarn mode) or Yarn application session cluster (yarn-application mode)
There are 2 important components in Flink interpreter: Scala shell & Python shell
- Scala shell is the entry point of Flink interpreter, it would create all the entry points of Flink program, such as ExecutionEnvironment,StreamExecutionEnvironment and TableEnvironment. Scala shell is responsible for compiling and running Scala code and sql.
- Python shell is the entry point of PyFlink, it is responsible for compiling and running Python code.
Configuration
The Flink interpreter can be configured with properties provided by Zeppelin (as following table). You can also add and set other Flink properties which are not listed in the table. For a list of additional properties, refer to Flink Available Properties.
| Property | Default | Description |
|---|---|---|
FLINK_HOME |
Location of Flink installation. It is must be specified, otherwise you can not use Flink in Zeppelin | |
HADOOP_CONF_DIR |
Location of hadoop conf, this is must be set if running in yarn mode | |
HIVE_CONF_DIR |
Location of hive conf, this is must be set if you want to connect to hive metastore | |
| flink.execution.mode | local | Execution mode of Flink, e.g. local | remote | yarn | yarn-application |
| flink.execution.remote.host | Host name of running JobManager. Only used for remote mode | |
| flink.execution.remote.port | Port of running JobManager. Only used for remote mode | |
| jobmanager.memory.process.size | 1024m | Total memory size of JobManager, e.g. 1024m. It is official Flink property |
| taskmanager.memory.process.size | 1024m | Total memory size of TaskManager, e.g. 1024m. It is official Flink property |
| taskmanager.numberOfTaskSlots | 1 | Number of slot per TaskManager |
| local.number-taskmanager | 4 | Total number of TaskManagers in local mode |
| yarn.application.name | Zeppelin Flink Session | Yarn app name |
| yarn.application.queue | default | queue name of yarn app |
| zeppelin.flink.uiWebUrl | User specified Flink JobManager url, it could be used in remote mode where Flink cluster is already started, or could be used as url template, e.g. https://knox-server:8443/gateway/cluster-topo/yarn/proxy/{{applicationId}}/ where {{applicationId}} is placeholder of yarn app id | |
| zeppelin.flink.run.asLoginUser | true | Whether run Flink job as the Zeppelin login user, it is only applied when running Flink job in hadoop yarn cluster and shiro is enabled |
| flink.udf.jars | Flink udf jars (comma separated), Zeppelin will register udf in these jars automatically for user. These udf jars could be either local files or hdfs files if you have hadoop installed. The udf name is the class name. | |
| flink.udf.jars.packages | Packages (comma separated) that would be searched for the udf defined in flink.udf.jars. Specifying this can reduce the number of classes to scan, otherwise all the classes in udf jar will be scanned. |
|
| flink.execution.jars | Additional user jars (comma separated), these jars could be either local files or hdfs files if you have hadoop installed. It can be used to specify Flink connector jars or udf jars (no udf class auto-registration like flink.udf.jars) |
|
| flink.execution.packages | Additional user packages (comma separated), e.g. org.apache.flink:flink-json:1.10.0 |
|
| zeppelin.flink.concurrentBatchSql.max | 10 | Max concurrent sql of Batch Sql (%flink.bsql) |
| zeppelin.flink.concurrentStreamSql.max | 10 | Max concurrent sql of Stream Sql (%flink.ssql) |
| zeppelin.pyflink.python | python | Python binary executable for PyFlink |
| table.exec.resource.default-parallelism | 1 | Default parallelism for Flink sql job |
| zeppelin.flink.scala.color | true | Whether display Scala shell output in colorful format |
| zeppelin.flink.scala.shell.tmp_dir | Temp folder for storing scala shell compiled jar | |
| zeppelin.flink.enableHive | false | Whether enable hive |
| zeppelin.flink.hive.version | 2.3.4 | Hive version that you would like to connect |
| zeppelin.flink.module.enableHive | false | Whether enable hive module, hive udf take precedence over Flink udf if hive module is enabled. |
| zeppelin.flink.maxResult | 1000 | max number of row returned by sql interpreter |
zeppelin.flink.job.check_interval |
1000 | Check interval (in milliseconds) to check Flink job progress |
flink.interpreter.close.shutdown_cluster |
true | Whether shutdown Flink cluster when closing interpreter |
zeppelin.interpreter.close.cancel_job |
true | Whether cancel Flink job when closing interpreter |
Interpreter Binding Mode
The default interpreter binding mode is globally shared. That means all notes share the same Flink interpreter which means they share the same Flink cluster.
In practice, we would recommend you to use isolated per note which means each note has own Flink interpreter without affecting each other (Each one has his own Flink cluster).
Execution Mode
Flink in Zeppelin supports 4 execution modes (flink.execution.mode):
- Local
- Remote
- Yarn
- Yarn Application
Local Mode
Running Flink in local mode will start a MiniCluster in local JVM. By default, the local MiniCluster use port 8081, so make sure this port is available in your machine,
otherwise you can configure rest.port to specify another port. You can also specify local.number-taskmanager and flink.tm.slot to customize the number of TM and number of slots per TM.
Because by default it is only 4 TM with 1 slot in this MiniCluster which may not be enough for some cases.
Remote Mode
Running Flink in remote mode will connect to an existing Flink cluster which could be standalone cluster or yarn session cluster. Besides specifying flink.execution.mode to be remote, you also need to specify
flink.execution.remote.host and flink.execution.remote.port to point to Flink job manager's rest api address.
Yarn Mode
In order to run Flink in Yarn mode, you need to make the following settings:
- Set
flink.execution.modeto beyarn - Set
HADOOP_CONF_DIRin Flink's interpreter setting orzeppelin-env.sh. - Make sure
hadoopcommand is on yourPATH. Because internally Flink will call commandhadoop classpathand load all the hadoop related jars in the Flink interpreter process
In this mode, Zeppelin would launch a Flink yarn session cluster for you and destroy it when you shutdown your Flink interpreter.
Yarn Application Mode
In the above yarn mode, there will be a separated Flink interpreter process on the Zeppelin server host. However, this may run out of resources when there are too many interpreter processes. So in practise, we would recommend you to use yarn application mode if you are using Flink 1.11 or afterwards (yarn application mode is only supported after Flink 1.11). In this mode Flink interpreter runs in the JobManager which is in yarn container. In order to run Flink in yarn application mode, you need to make the following settings:
- Set
flink.execution.modeto beyarn-application - Set
HADOOP_CONF_DIRin Flink's interpreter setting orzeppelin-env.sh. - Make sure
hadoopcommand is on yourPATH. Because internally flink will call commandhadoop classpathand load all the hadoop related jars in Flink interpreter process
Flink Scala
Scala is the default language of Flink on Zeppelin(%flink), and it is also the entry point of Flink interpreter. Underneath Flink interpreter will create Scala shell
which would create several built-in variables, including ExecutionEnvironment,StreamExecutionEnvironment and so on.
So don't create these Flink environment variables again, otherwise you might hit weird issues. The Scala code you write in Zeppelin will be submitted to this Scala shell.
Here are the builtin variables created in Flink Scala shell.
- senv (StreamExecutionEnvironment),
- benv (ExecutionEnvironment)
- stenv (StreamTableEnvironment for blink planner (aka. new planner))
- btenv (BatchTableEnvironment for blink planner (aka. new planner))
- z (ZeppelinContext)
Blink/Flink Planner
After Zeppelin 0.11, we remove the support of flink planner (aka. old planner) which is also removed after Flink 1.14.
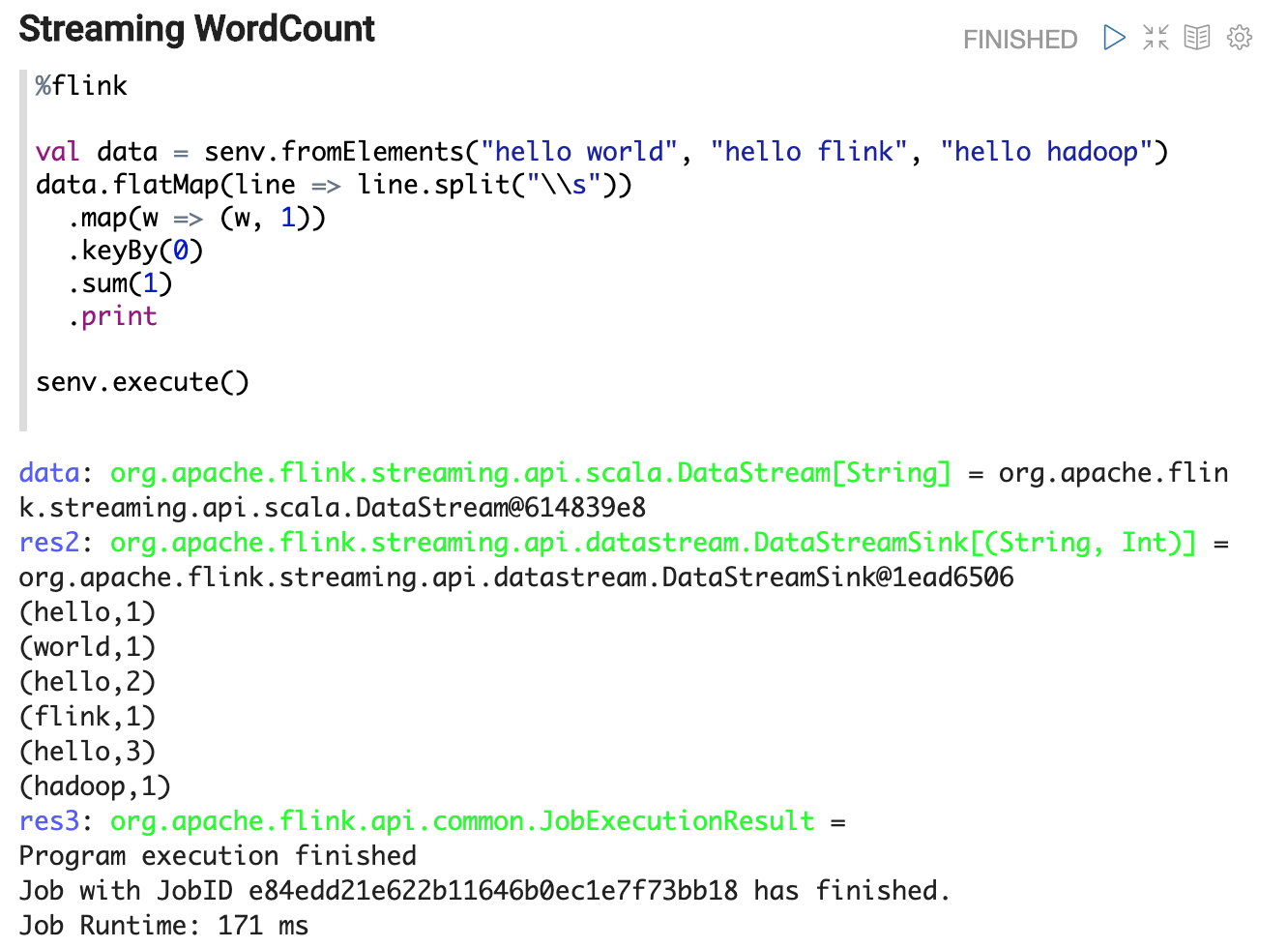
Stream WordCount Example
You can write whatever Scala code in Zeppelin.
e.g. in the following example, we write a classical streaming wordcount example.
Code Completion
You can type tab for code completion.
ZeppelinContext
ZeppelinContext provides some additional functions and utilities.
See Zeppelin-Context for more details.
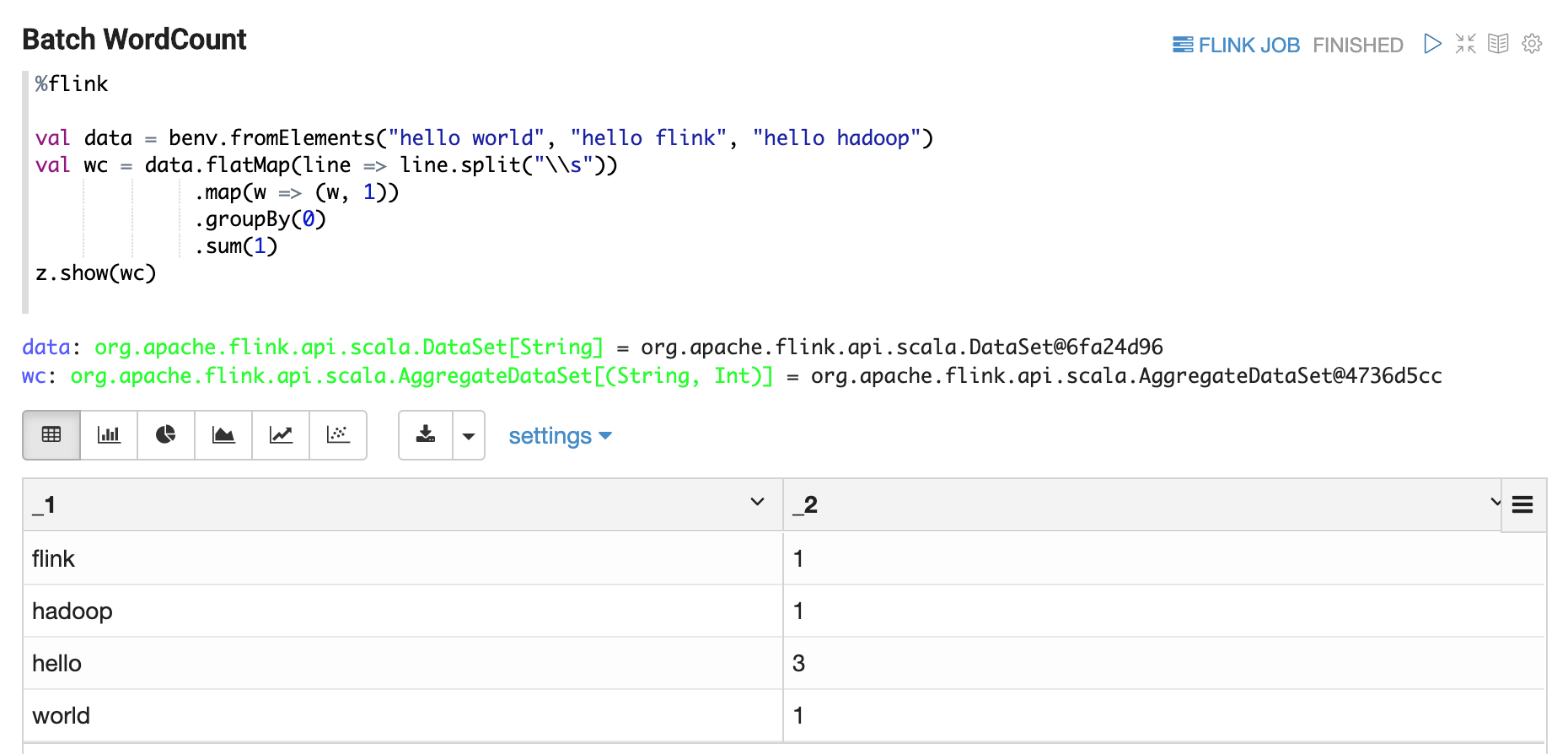
For Flink interpreter, you can use z to display Flink Dataset/Table.
e.g. you can use z.show to display DataSet, Batch Table, Stream Table.
- z.show(DataSet)
- z.show(Batch Table)
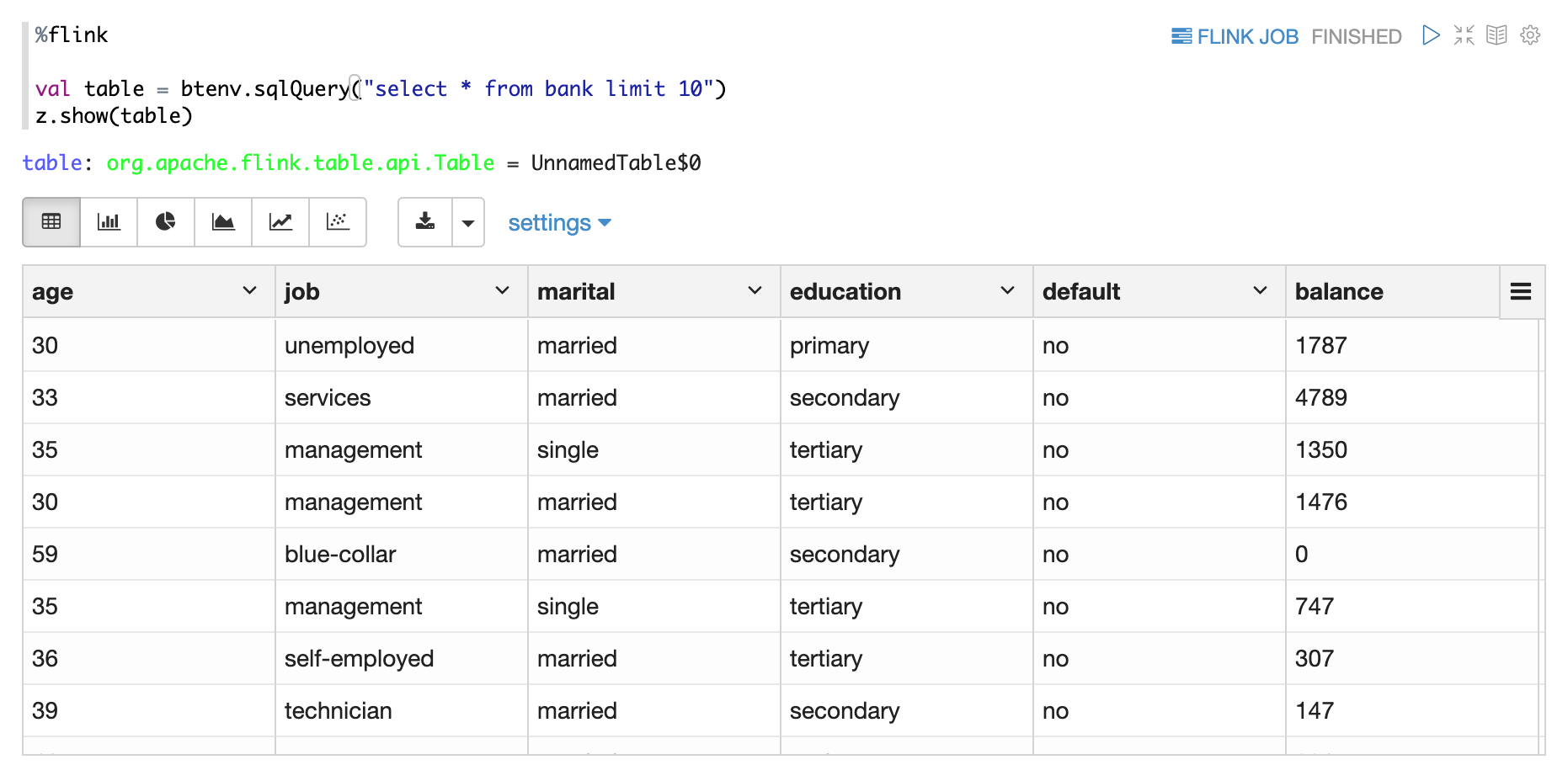
- z.show(Stream Table)
Flink SQL
In Zeppelin, there are 2 kinds of Flink sql interpreter you can use
%flink.ssqlStreaming Sql interpreter which launch Flink streaming job viaStreamTableEnvironment%flink.bsqlBatch Sql interpreter which launch Flink batch job viaBatchTableEnvironment
Flink Sql interpreter in Zeppelin is equal to Flink Sql-client + many other enhancement features.
Enhancement SQL Features
Support batch SQL and streaming sql together.
In Flink Sql-client, either you run streaming sql or run batch sql in one session. You can not run them together.
But in Zeppelin, you can do that. %flink.ssql is used for running streaming sql, while %flink.bsql is used for running batch sql.
Batch/Streaming Flink jobs run in the same Flink session cluster.
Support multiple statements
You can write multiple sql statements in one paragraph, each sql statement is separated by semicolon.
Comment support
2 kinds of sql comments are supported in Zeppelin:
- Single line comment start with
-- - Multiple line comment around with
/* */

Job parallelism setting
You can set the sql parallelism via paragraph local property: parallelism

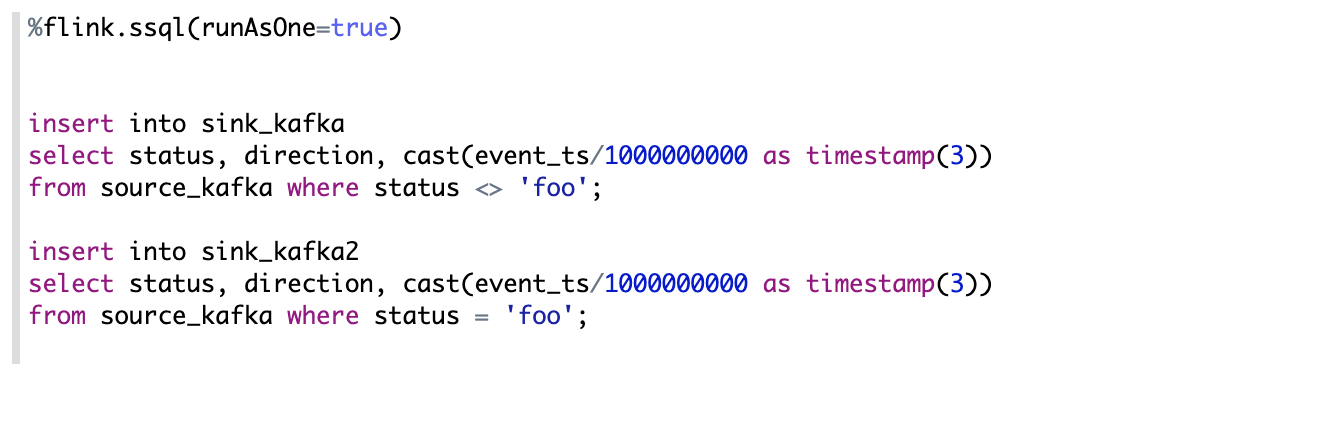
Support multiple insert
Sometimes you have multiple insert statements which read the same source,
but write to different sinks. By default, each insert statement would launch a separated Flink job,
but you can set paragraph local property: runAsOne to be true to run them in one single Flink job.
Set job name
You can set Flink job name for insert statement via setting paragraph local property: jobName. To be noticed,
you can only set job name for insert statement. Select statement is not supported yet.
And this kind of setting only works for single insert statement. It doesn't work for multiple insert we mentioned above.

Streaming Data Visualization
Zeppelin can visualize the select sql result of Flink streaming job. Overall it supports 3 modes:
- Single
- Update
- Append
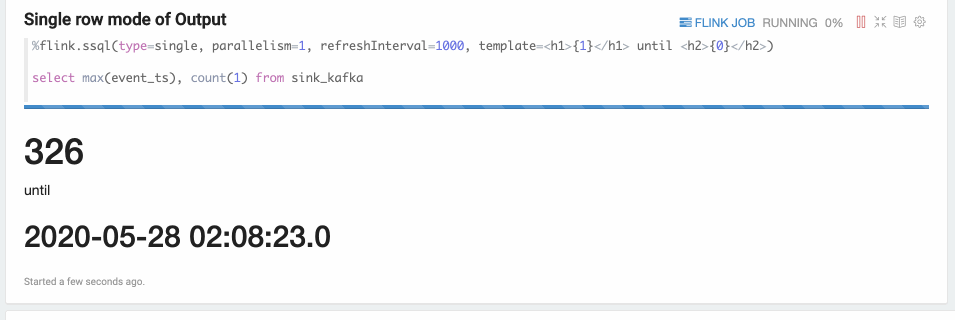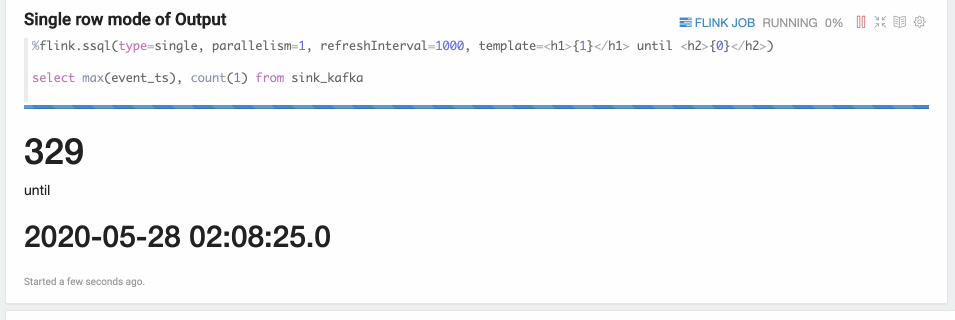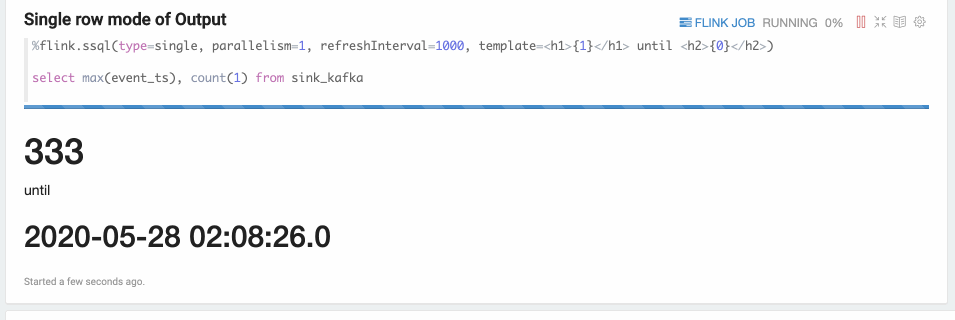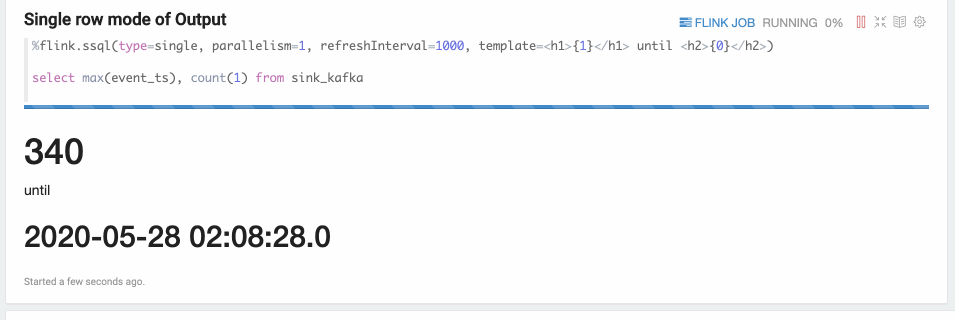
Single Mode
Single mode is for the case when the result of sql statement is always one row,
such as the following example. The output format is HTML,
and you can specify paragraph local property template for the final output content template.
You can use {i} as placeholder for the ith column of result.
Update Mode
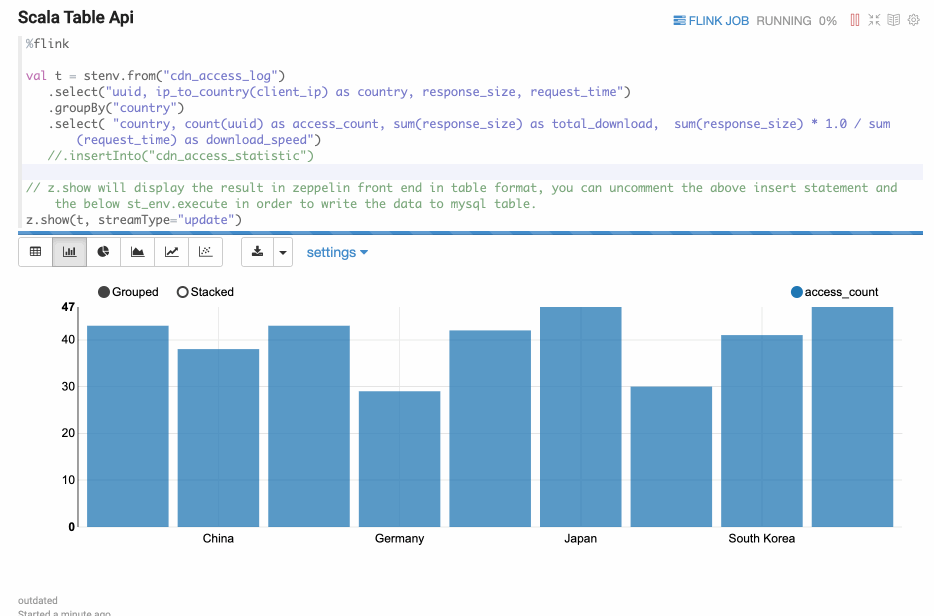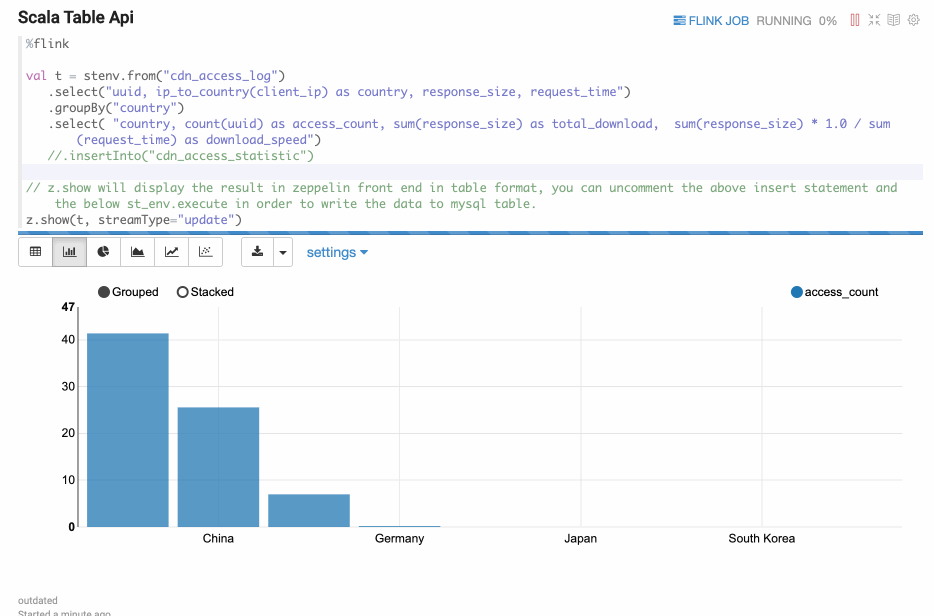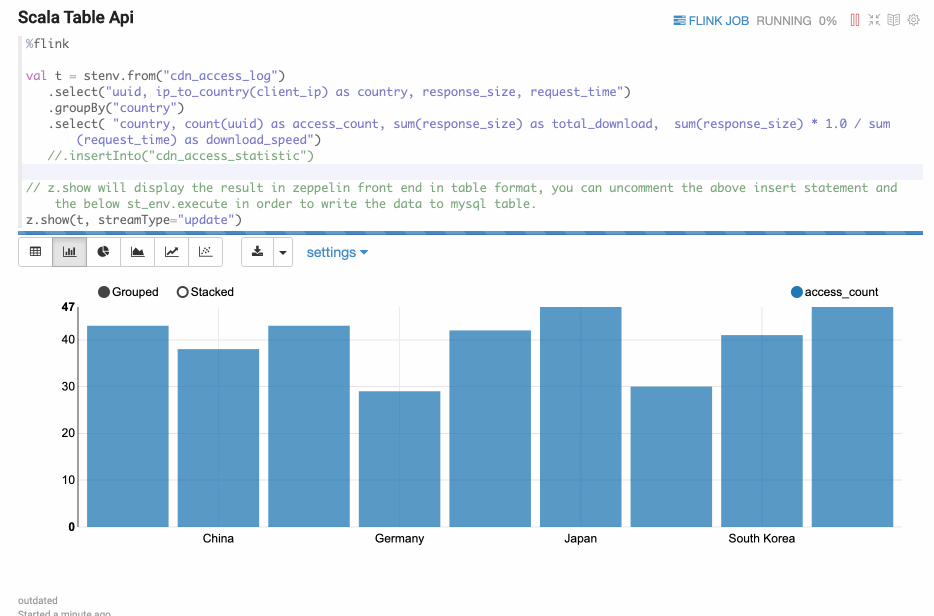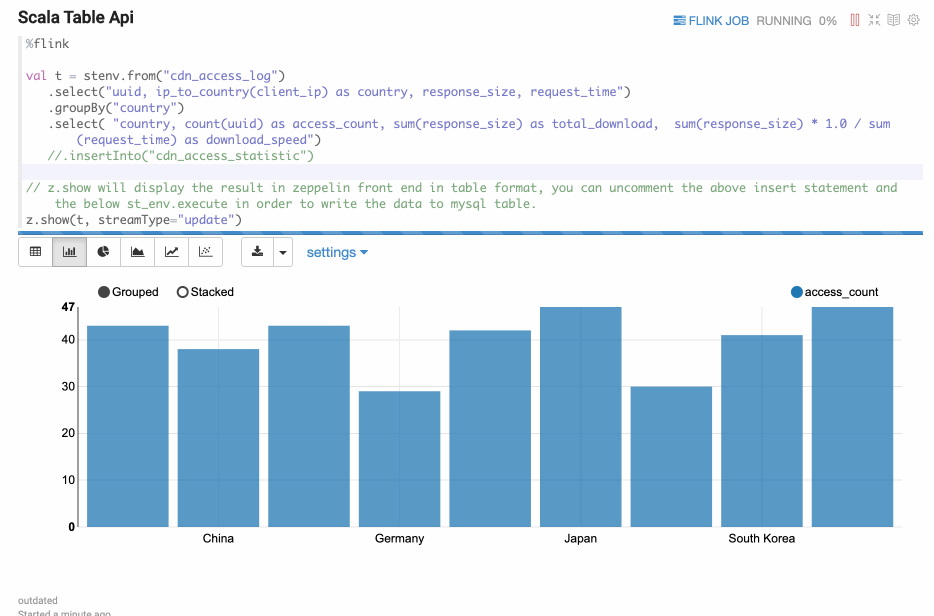
Update mode is suitable for the case when the output is more than one rows, and will always be updated continuously. Here’s one example where we use group by.
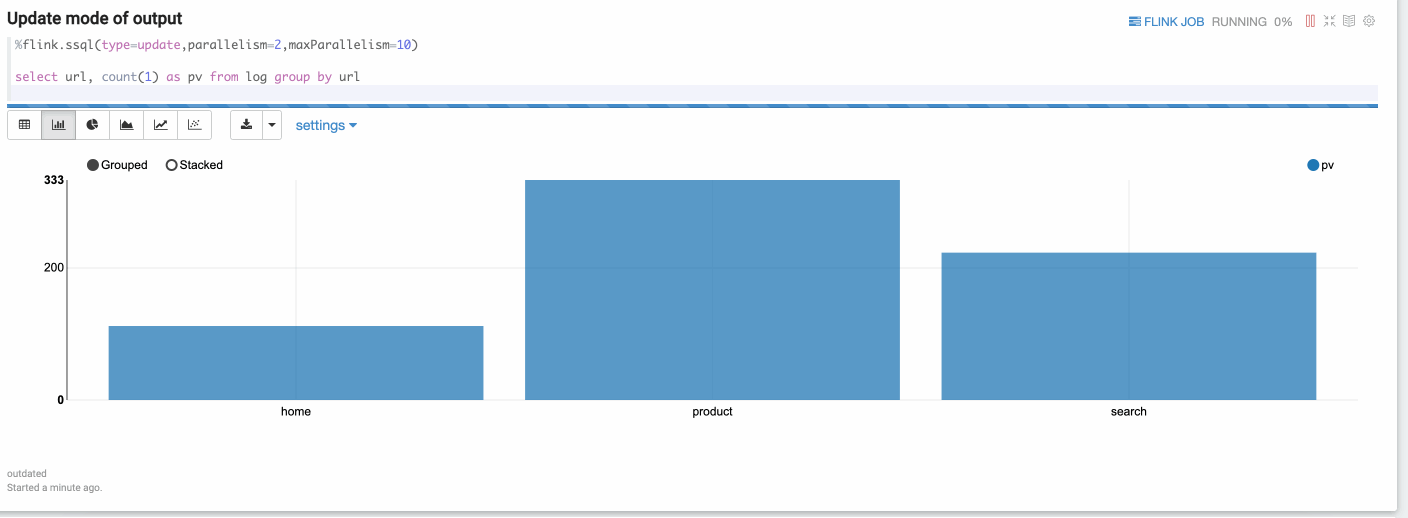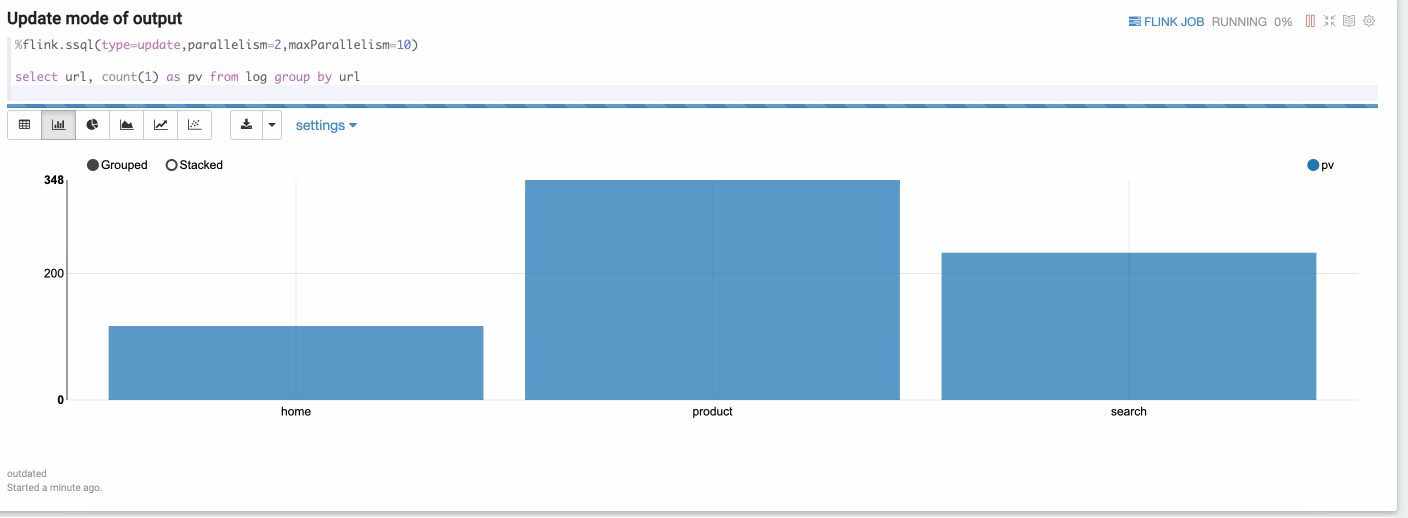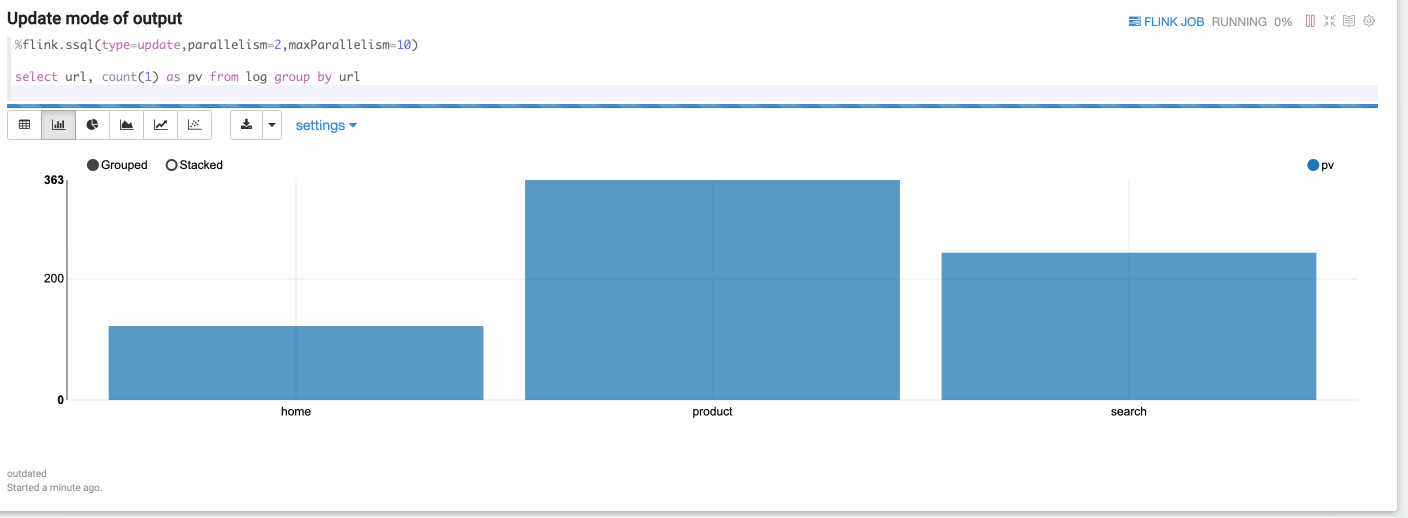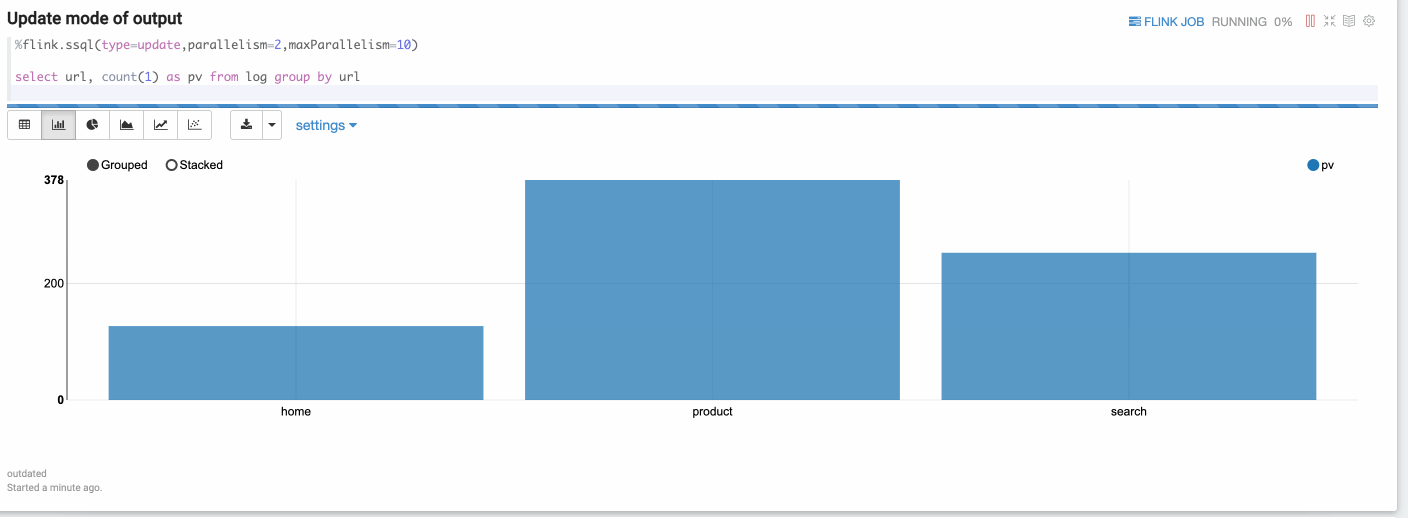
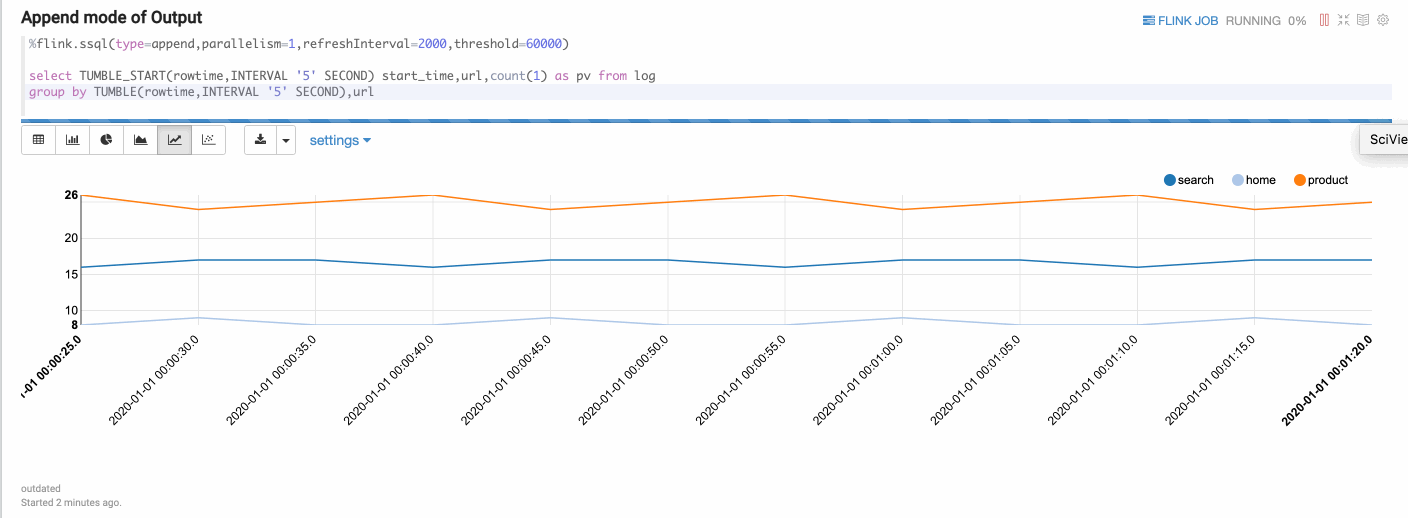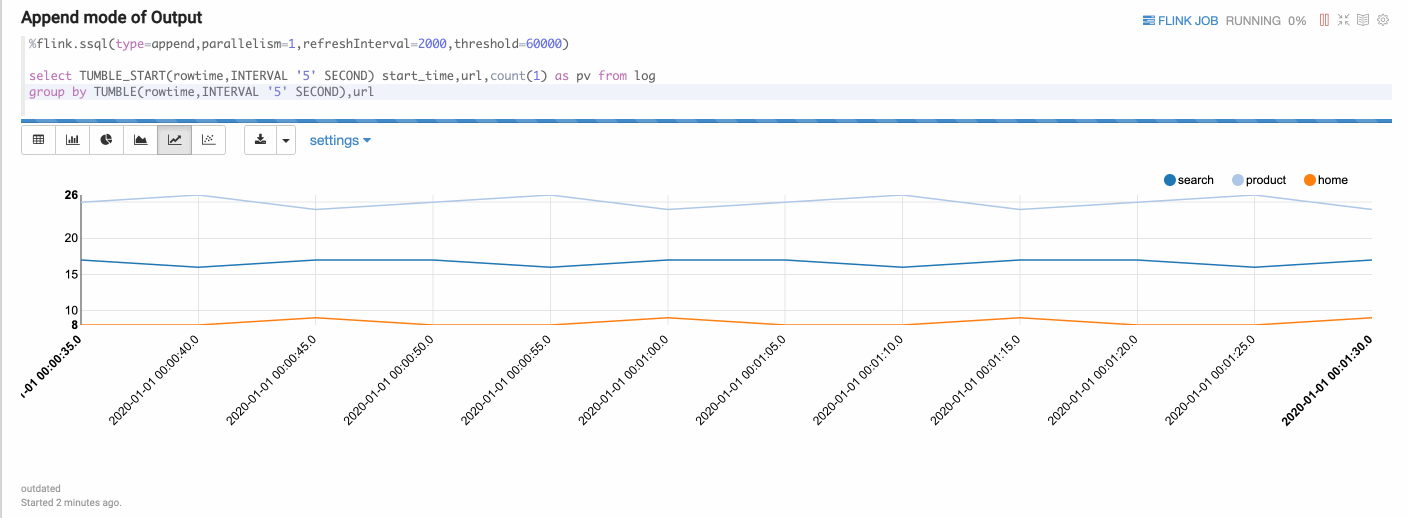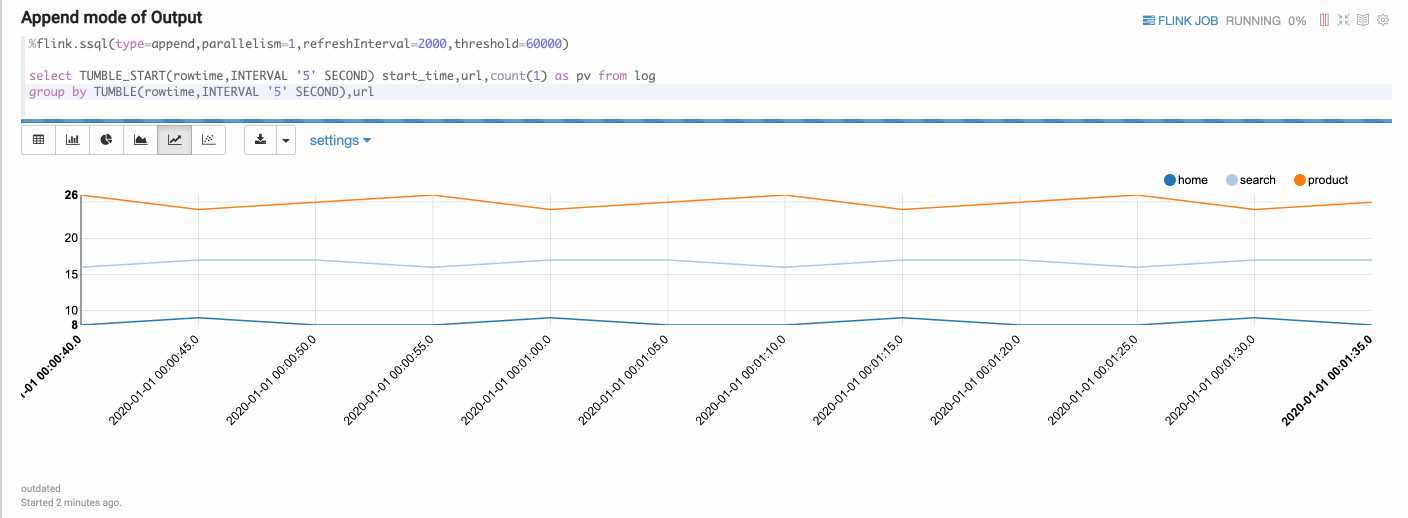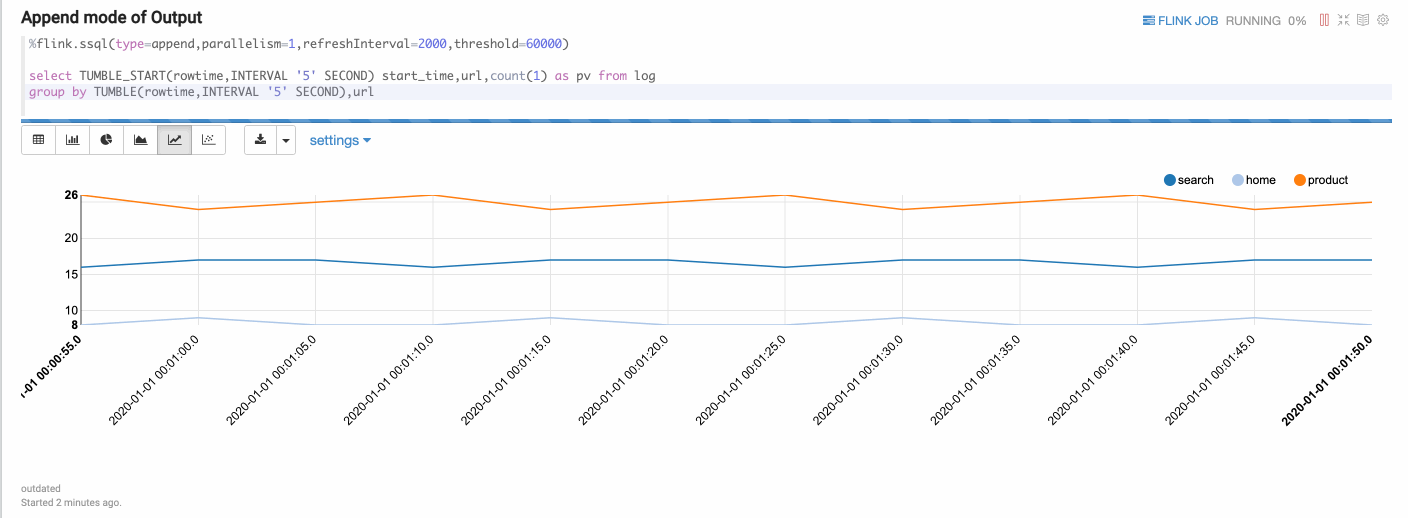
Append Mode
Append mode is suitable for the scenario where output data is always appended. E.g. the following example which use tumble window.
PyFlink
PyFlink is Python entry point of Flink on Zeppelin, internally Flink interpreter will create Python shell which would create Flink's environment variables (including ExecutionEnvironment, StreamExecutionEnvironment and so on). To be noticed, the java environment behind Pyflink is created in Scala shell. That means underneath Scala shell and Python shell share the same environment. These are variables created in Python shell.
s_env(StreamExecutionEnvironment),b_env(ExecutionEnvironment)st_env(StreamTableEnvironment for blink planner (aka. new planner))bt_env(BatchTableEnvironment for blink planner (aka. new planner))
Configure PyFlink
There are 3 things you need to configure to make Pyflink work in Zeppelin.
- Install pyflink e.g. ( pip install apache-flink==1.11.1 ). If you need to use Pyflink udf, then you to install pyflink on all the task manager nodes. That means if you are using yarn, then all the yarn nodes need to install pyflink.
- Copy
pythonfolder under${FLINK_HOME}/optto${FLINK_HOME/lib. - Set
zeppelin.pyflink.pythonas the python executable path. By default, it is the python inPATH. In case you have multiple versions of python installed, you need to configurezeppelin.pyflink.pythonas the python version you want to use.
How to use PyFlink
There are 2 ways to use PyFlink in Zeppelin
%flink.pyflink%flink.ipyflink
%flink.pyflink is much simple and easy, you don't need to do anything except the above setting,
but its function is also limited. We suggest you to use %flink.ipyflink which provides almost the same user experience like jupyter.
Configure IPyFlink
If you don't have anaconda installed, then you need to install the following 3 libraries.
pip install jupyter
pip install grpcio
pip install protobuf
If you have anaconda installed, then you only need to install following 2 libraries.
pip install grpcio
pip install protobuf
ZeppelinContext is also available in PyFlink, you can use it almost the same as in Flink Scala.
Check the Python doc for more features of IPython.
Third party dependencies
It is very common to have third party dependencies when you write Flink job in whatever languages (Scala, Python, Sql). It is very easy to add dependencies in IDE (e.g. add dependency in pom.xml), but how can you do that in Zeppelin ? Mainly there are 2 settings you can use to add third party dependencies
- flink.execution.packages
- flink.execution.jars
flink.execution.packages
This is the recommended way of adding dependencies. Its implementation is the same as adding
dependencies in pom.xml. Underneath it would download all the packages and its transitive dependencies
from maven repository, then put them on the classpath. Here's one example of how to add kafka connector of Flink 1.10 via inline configuration.
%flink.conf
flink.execution.packages org.apache.flink:flink-connector-kafka_2.11:1.10.0,org.apache.flink:flink-connector-kafka-base_2.11:1.10.0,org.apache.flink:flink-json:1.10.0
The format is artifactGroup:artifactId:version, if you have multiple packages,
then separate them with comma. flink.execution.packages requires internet accessible.
So if you can not access internet, you need to use flink.execution.jars instead.
flink.execution.jars
If your Zeppelin machine can not access internet or your dependencies are not deployed to maven repository,
then you can use flink.execution.jars to specify the jar files you depend on (each jar file is separated with comma)
Here's one example of how to add kafka dependencies(including kafka connector and its transitive dependencies) via flink.execution.jars
%flink.conf
flink.execution.jars /usr/lib/flink-kafka/target/flink-kafka-1.0-SNAPSHOT.jar
Flink UDF
There are 4 ways you can define UDF in Zeppelin.
- Write Scala UDF
- Write PyFlink UDF
- Create UDF via SQL
- Configure udf jar via flink.udf.jars
Scala UDF
%flink
class ScalaUpper extends ScalarFunction {
def eval(str: String) = str.toUpperCase
}
btenv.registerFunction("scala_upper", new ScalaUpper())
It is very straightforward to define scala udf almost the same as what you do in IDE.
After creating udf class, you need to register it via btenv.
You can also register it via stenv which share the same Catalog with btenv.
Python UDF
%flink.pyflink
class PythonUpper(ScalarFunction):
def eval(self, s):
return s.upper()
bt_env.register_function("python_upper", udf(PythonUpper(), DataTypes.STRING(), DataTypes.STRING()))
It is also very straightforward to define Python udf almost the same as what you do in IDE.
After creating udf class, you need to register it via bt_env.
You can also register it via st_env which share the same Catalog with bt_env.
UDF via SQL
Some simple udf can be written in Zeppelin. But if the udf logic is very complicated, then it is better to write it in IDE, then register it in Zeppelin as following
%flink.ssql
CREATE FUNCTION myupper AS 'org.apache.zeppelin.flink.udf.JavaUpper';
But this kind of approach requires the udf jar must be on CLASSPATH,
so you need to configure flink.execution.jars to include this udf jar on CLASSPATH, such as following:
%flink.conf
flink.execution.jars /usr/lib/flink-udf-1.0-SNAPSHOT.jar
flink.udf.jars
The above 3 approaches all have some limitations:
- It is suitable to write simple Scala udf or Python udf in Zeppelin, but not suitable to write very complicated udf in Zeppelin. Because notebook doesn't provide advanced features compared to IDE, such as package management, code navigation and etc.
- It is not easy to share the udf between notes or users, you have to run the paragraph of defining udf in each flink interpreter.
So when you have many udfs or udf logic is very complicated and you don't want to register them by yourself every time, then you can use flink.udf.jars
- Step 1. Create a udf project in your IDE, write your udf there.
- Step 2. Set
flink.udf.jarsto point to the udf jar you build from your udf project
For example,
%flink.conf
flink.execution.jars /usr/lib/flink-udf-1.0-SNAPSHOT.jar
Zeppelin would scan this jar, find out all the udf classes and then register them automatically for you.
The udf name is the class name. For example, here's the output of show functions after specifing the above udf jars in flink.udf.jars
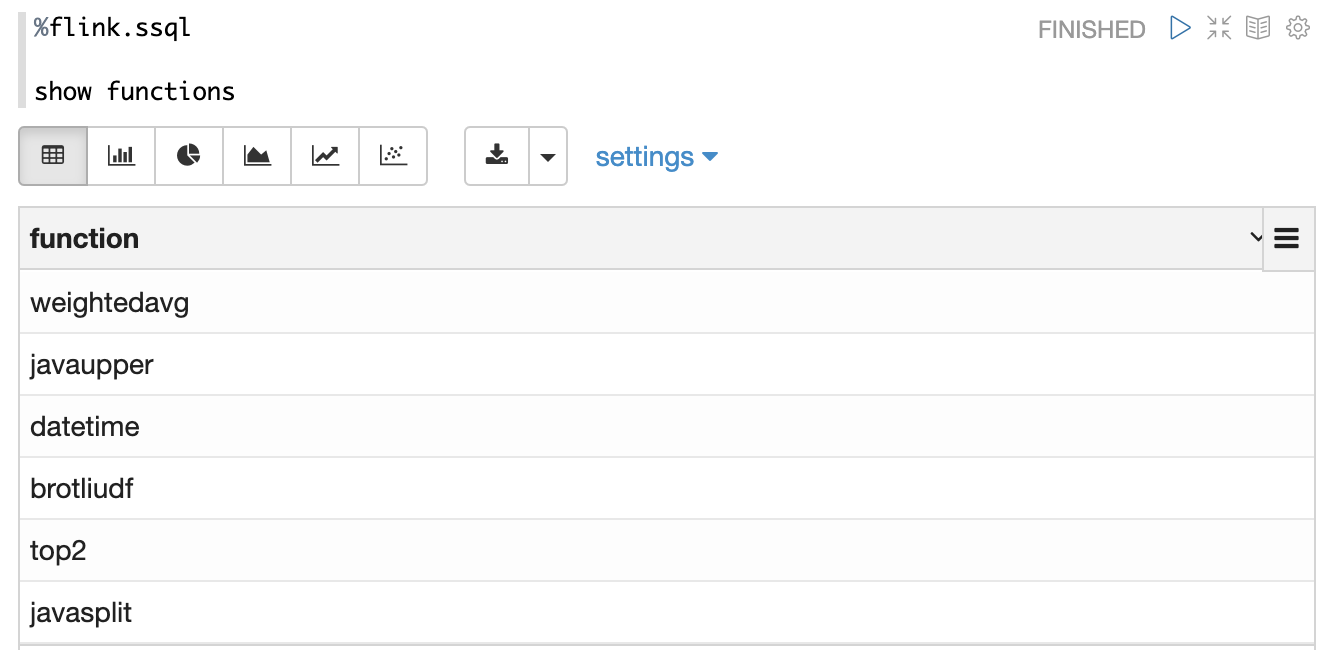
By default, Zeppelin would scan all the classes in this jar,
so it would be pretty slow if your jar is very big specially when your udf jar has other dependencies.
So in this case we would recommend you to specify flink.udf.jars.packages to specify the package to scan,
this can reduce the number of classes to scan and make the udf detection much faster.
How to use Hive
In order to use Hive in Flink, you have to make the following settings.
- Set
zeppelin.flink.enableHiveto be true - Set
zeppelin.flink.hive.versionto be the hive version you are using. - Set
HIVE_CONF_DIRto be the location wherehive-site.xmlis located. Make sure hive metastore is started and you have configuredhive.metastore.urisinhive-site.xml - Copy the following dependencies to the lib folder of flink installation.
- flink-connector-hive_2.11–*.jar
- flink-hadoop-compatibility_2.11–*.jar
- hive-exec-2.x.jar (for hive 1.x, you need to copy hive-exec-1.x.jar, hive-metastore-1.x.jar, libfb303–0.9.2.jar and libthrift-0.9.2.jar)
Paragraph local properties
In the section of Streaming Data Visualization, we demonstrate the different visualization type via paragraph local properties: type.
In this section, we will list and explain all the supported local properties in Flink interpreter.
| Property | Default | Description |
|---|---|---|
| type | Used in %flink.ssql to specify the streaming visualization type (single, update, append) | |
| refreshInterval | 3000 | Used in `%flink.ssql` to specify frontend refresh interval for streaming data visualization. |
| template | {0} | Used in `%flink.ssql` to specify html template for `single` type of streaming data visualization, And you can use `{i}` as placeholder for the {i}th column of the result. |
| parallelism | Used in %flink.ssql & %flink.bsql to specify the flink sql job parallelism | |
| maxParallelism | Used in %flink.ssql & %flink.bsql to specify the flink sql job max parallelism in case you want to change parallelism later. For more details, refer this [link](https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/parallel.html#setting-the-maximum-parallelism) | |
| savepointDir | If you specify it, then when you cancel your flink job in Zeppelin, it would also do savepoint and store state in this directory. And when you resume your job, it would resume from this savepoint. | |
| execution.savepoint.path | When you resume your job, it would resume from this savepoint path. | |
| resumeFromSavepoint | Resume flink job from savepoint if you specify savepointDir. | |
| resumeFromLatestCheckpoint | Resume flink job from latest checkpoint if you enable checkpoint. | |
| runAsOne | false | All the insert into sql will run in a single flink job if this is true. |
Tutorial Notes
Zeppelin is shipped with several Flink tutorial notes which may be helpful for you. You can check for more features in the tutorial notes.
Community
Join our community to discuss with others.