R Interpreter for Apache Zeppelin
Overview
R is a free software environment for statistical computing and graphics.
To run R code and visualize plots in Apache Zeppelin, you will need R on your master node (or your dev laptop).
- For Centos:
yum install R R-devel libcurl-devel openssl-devel - For Ubuntu:
apt-get install r-base
Validate your installation with a simple R command:
R -e "print(1+1)"
To enjoy plots, install additional libraries with:
+ devtools with `R -e "install.packages('devtools', repos = 'http://cran.us.r-project.org')"`
+ knitr with `R -e "install.packages('knitr', repos = 'http://cran.us.r-project.org')"`
+ ggplot2 with `R -e "install.packages('ggplot2', repos = 'http://cran.us.r-project.org')"`
+ Other vizualisation librairies: `R -e "install.packages(c('devtools','mplot', 'googleVis'), repos = 'http://cran.us.r-project.org'); require(devtools); install_github('ramnathv/rCharts')"`
We recommend you to also install the following optional R libraries for happy data analytics:
- glmnet
- pROC
- data.table
- caret
- sqldf
- wordcloud
Configuration
To run Zeppelin with the R Interpreter, the SPARK_HOME environment variable must be set. The best way to do this is by editing conf/zeppelin-env.sh.
If it is not set, the R Interpreter will not be able to interface with Spark.
You should also copy conf/zeppelin-site.xml.template to conf/zeppelin-site.xml. That will ensure that Zeppelin sees the R Interpreter the first time it starts up.
Using the R Interpreter
By default, the R Interpreter appears as two Zeppelin Interpreters, %r and %knitr.
%r will behave like an ordinary REPL. You can execute commands as in the CLI.

R base plotting is fully supported
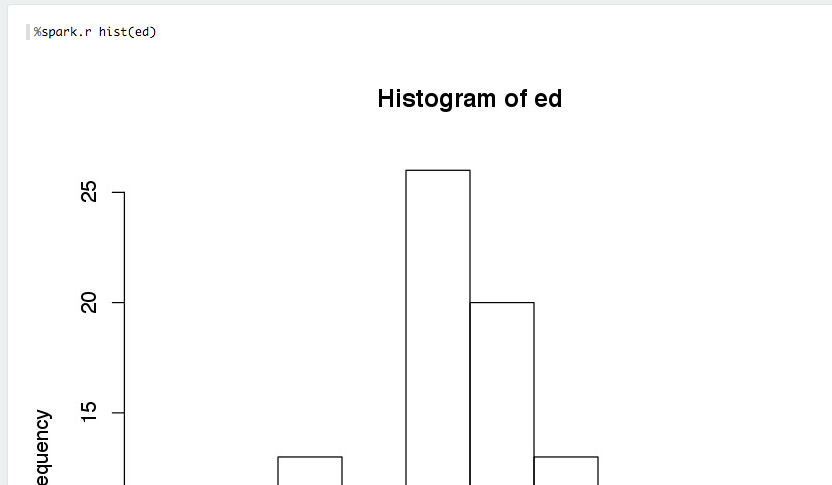
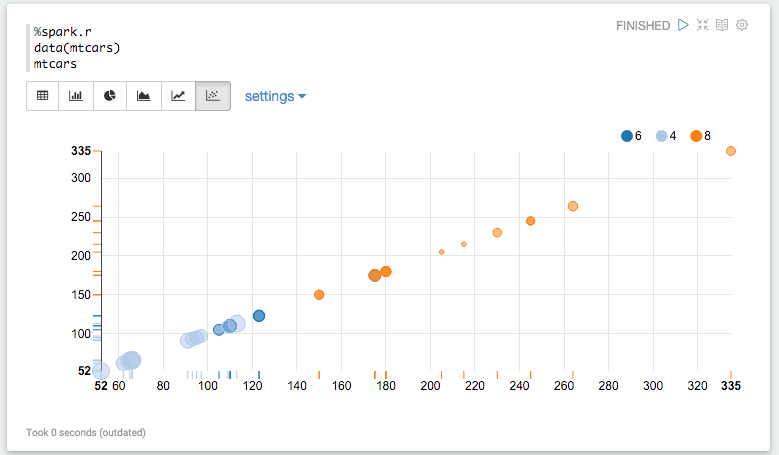
If you return a data.frame, Zeppelin will attempt to display it using Zeppelin's built-in visualizations.
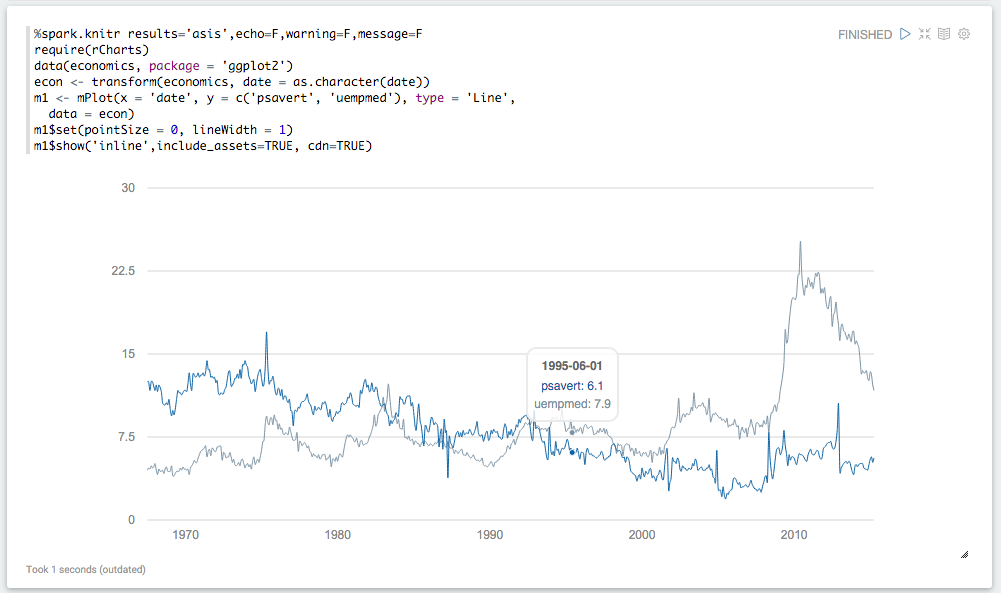
%knitr interfaces directly against knitr, with chunk options on the first line:

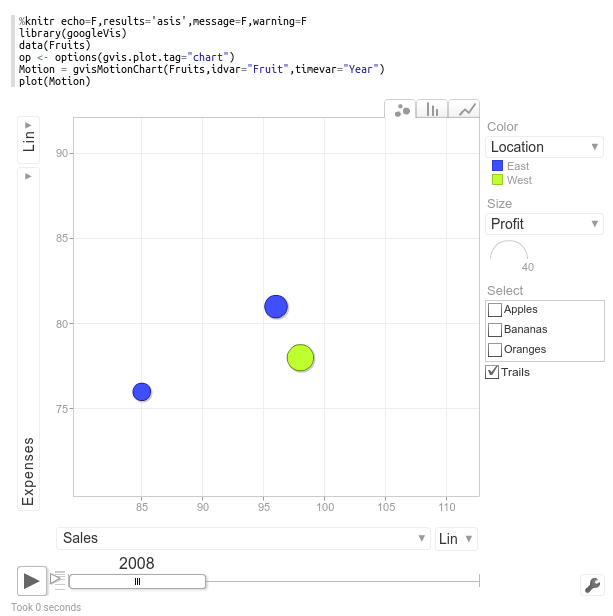
The two interpreters share the same environment. If you define a variable from %r, it will be within-scope if you then make a call using knitr.
Using SparkR & Moving Between Languages
If SPARK_HOME is set, the SparkR package will be loaded automatically:
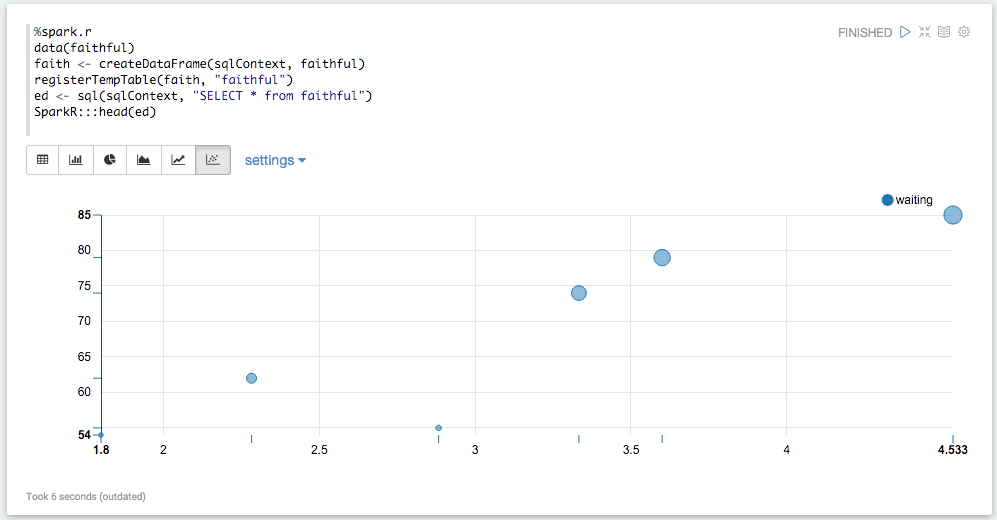
The Spark Context and SQL Context are created and injected into the local environment automatically as sc and sql.
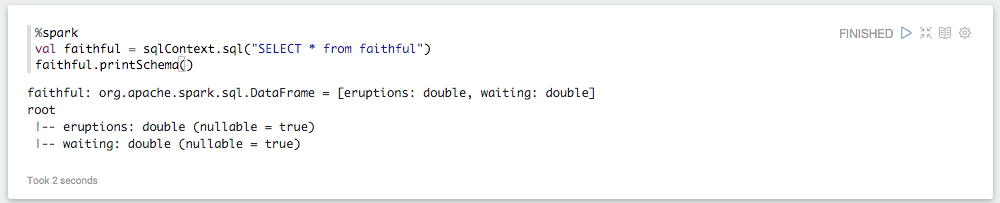
The same context are shared with the %spark, %sql and %pyspark interpreters:
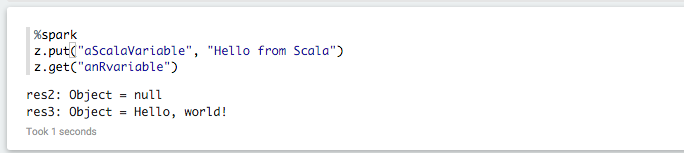
You can also make an ordinary R variable accessible in scala and Python:

And vice versa:
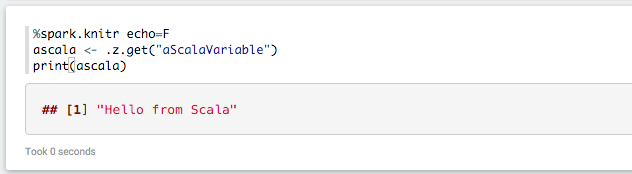
Caveats & Troubleshooting
Almost all issues with the R interpreter turned out to be caused by an incorrectly set
SPARK_HOME. The R interpreter must load a version of theSparkRpackage that matches the running version of Spark, and it does this by searchingSPARK_HOME. If Zeppelin isn't configured to interface with Spark inSPARK_HOME, the R interpreter will not be able to connect to Spark.The
knitrenvironment is persistent. If you run a chunk from Zeppelin that changes a variable, then run the same chunk again, the variable has already been changed. Use immutable variables.(Note that
%spark.rand%rare two different ways of calling the same interpreter, as are%spark.knitrand%knitr. By default, Zeppelin puts the R interpreters in the%spark.Interpreter Group.Using the
%rinterpreter, if you return a data.frame, HTML, or an image, it will dominate the result. So if you execute three commands, and one ishist(), all you will see is the histogram, not the results of the other commands. This is a Zeppelin limitation.If you return a data.frame (for instance, from calling
head()) from the%spark.rinterpreter, it will be parsed by Zeppelin's built-in data visualization system.Why
knitrInstead ofrmarkdown? Why nohtmlwidgets? In order to supporthtmlwidgets, which has indirect dependencies,rmarkdownusespandoc, which requires writing to and reading from disc. This makes it many times slower thanknitr, which can operate entirely in RAM.Why no
ggvisorshiny? Supportingshinywould require integrating a reverse-proxy into Zeppelin, which is a task.Max OS X & case-insensitive filesystem. If you try to install on a case-insensitive filesystem, which is the Mac OS X default, maven can unintentionally delete the install directory because
randRbecome the same subdirectory.Error
unable to start device X11with the repl interpreter. Check your shell login scripts to see if they are adjusting theDISPLAYenvironment variable. This is common on some operating systems as a workaround for ssh issues, but can interfere with R plotting.akka Library Version or
TTransporterrors. This can happen if you try to run Zeppelin with a SPARK_HOME that has a version of Spark other than the one specified with-Pspark-1.xwhen Zeppelin was compiled.