Generic JDBC Interpreter for Apache Zeppelin
Overview
This interpreter lets you create a JDBC connection to any data source, by now it has been tested with:
- Postgres
- MySql
- MariaDB
- Redshift
- Apache Hive
- Apache Phoenix
- Apache Drill (Details on using Drill JDBC Driver)
- Apache Tajo
If someone else used another database please report how it works to improve functionality.
Create Interpreter
When you create a interpreter by default use PostgreSQL with the next properties:
| name | value |
|---|---|
| common.max_count | 1000 |
| default.driver | org.postgresql.Driver |
| default.password | ******** |
| default.url | jdbc:postgresql://localhost:5432/ |
| default.user | gpadmin |
It is not necessary to add driver jar to the classpath for PostgreSQL as it is included in Zeppelin.
Simple connection
Prior to creating the interpreter it is necessary to add maven coordinate or path of the JDBC driver to the Zeppelin classpath. To do this you must edit dependencies artifact(ex. mysql:mysql-connector-java:5.1.38) in interpreter menu as shown:
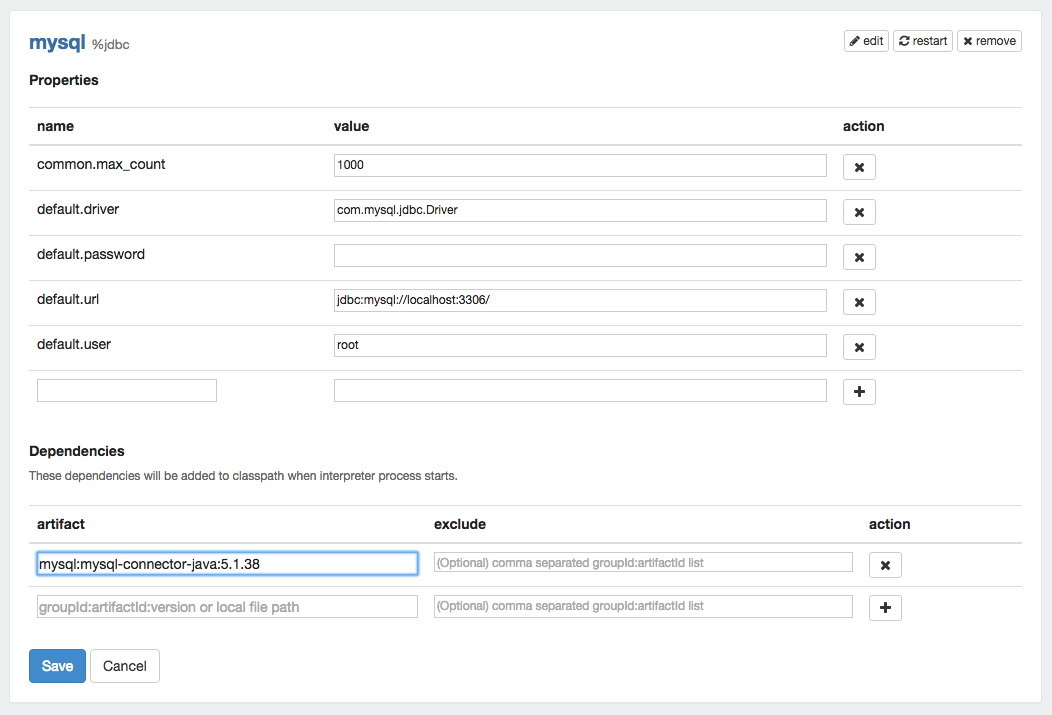
To create the interpreter you need to specify connection parameters as shown in the table.
| name | value |
|---|---|
| common.max_count | 1000 |
| default.driver | driver name |
| default.password | ******** |
| default.url | jdbc url |
| default.user | user name |
Multiple connections
JDBC interpreter also allows connections to multiple data sources. It is necessary to set a prefix for each connection to reference it in the paragraph in the form of %jdbc(prefix). Before you create the interpreter it is necessary to add each driver's maven coordinates or JDBC driver's jar file path to the Zeppelin classpath. To do this you must edit the dependencies of JDBC interpreter in interpreter menu as following:
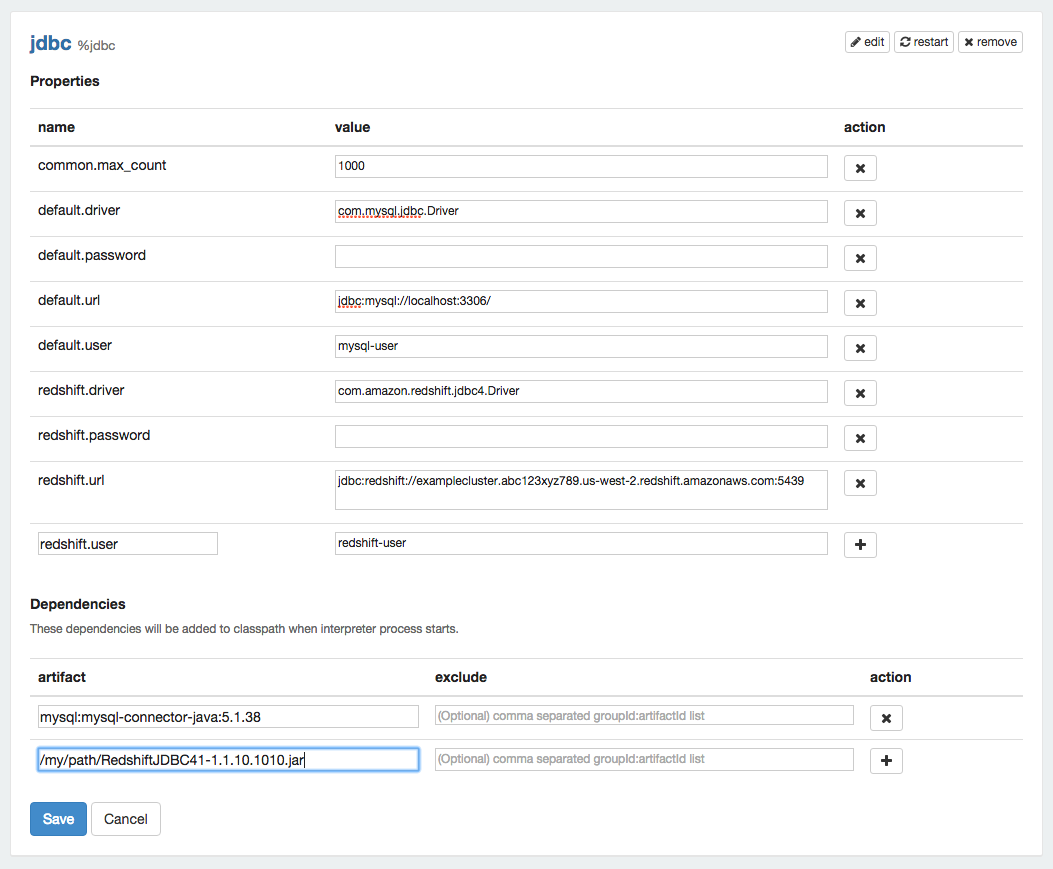
You can add all the jars you need to make multiple connections into the same JDBC interpreter. To create the interpreter you must specify the parameters. For example we will create two connections to MySQL and Redshift, the respective prefixes are default and redshift:
| name | value |
|---|---|
| common.max_count | 1000 |
| default.driver | com.mysql.jdbc.Driver |
| default.password | ******** |
| default.url | jdbc:mysql://localhost:3306/ |
| default.user | mysql-user |
| redshift.driver | com.amazon.redshift.jdbc4.Driver |
| redshift.password | ******** |
| redshift.url | jdbc:redshift://examplecluster.abc123xyz789.us-west-2.redshift.amazonaws.com:5439 |
| redshift.user | redshift-user |
Bind to Notebook
In the Notebook click on the settings icon at the top-right corner. Use select/deselect to specify the interpreters to be used in the Notebook.
More Properties
You can modify the interpreter configuration in the Interpreter section. The most common properties are as follows, but you can specify other properties that need to be connected.
| Property Name | Description |
|---|---|
| {prefix}.url | JDBC URL to connect, the URL must include the name of the database |
| {prefix}.user | JDBC user name |
| {prefix}.password | JDBC password |
| {prefix}.driver | JDBC driver name. |
| common.max_result | Max number of SQL result to display to prevent the browser overload. This is common properties for all connections |
To develop this functionality use this method. For example if a connection needs a schema parameter, it would have to add the property as follows:
| name | value |
|---|---|
| {prefix}.schema | schema_name |
Examples
Hive
Properties
| Name | Value |
|---|---|
| hive.driver | org.apache.hive.jdbc.HiveDriver |
| hive.url | jdbc:hive2://localhost:10000 |
| hive.user | hiveuser |
| hive.password | hivepassword |
Dependencies
| Artifact | Excludes |
|---|---|
| org.apache.hive:hive-jdbc:0.14.0 | |
| org.apache.hadoop:hadoop-common:2.6.0 |
Phoenix
Phoenix supports thick and thin connection types:
- Thick client is faster, but must connect directly to ZooKeeper and HBase RegionServers.
- Thin client has fewer dependencies and connects through a Phoenix Query Server instance.
Use the appropriate phoenix.driver and phoenix.url for your connection type.
Properties:
| Name | Value | Description |
|---|---|---|
| phoenix.driver | org.apache.phoenix.jdbc.PhoenixDriver | 'Thick Client', connects directly to Phoenix |
| phoenix.driver | org.apache.phoenix.queryserver.client.Driver | 'Thin Client', connects via Phoenix Query Server |
| phoenix.url | jdbc:phoenix:localhost:2181:/hbase-unsecure | 'Thick Client', connects directly to Phoenix |
| phoenix.url | jdbc:phoenix:thin:url=http://localhost:8765;serialization=PROTOBUF | 'Thin Client', connects via Phoenix Query Server |
| phoenix.user | phoenixuser | |
| phoenix.password | phoenixpassword |
Dependencies:
Include the dependency for your connection type (it should be only one of the following).
| Artifact | Excludes | Description |
|---|---|---|
| org.apache.phoenix:phoenix-core:4.4.0-HBase-1.0 | 'Thick Client', connects directly to Phoenix | |
| org.apache.phoenix:phoenix-server-client:4.7.0-HBase-1.1 | 'Thin Client' for Phoenix 4.7, connects via Phoenix Query Server | |
| org.apache.phoenix:phoenix-queryserver-client:4.8.0-HBase-1.2 | 'Thin Client' for Phoenix 4.8+, connects via Phoenix Query Server |
Tajo
Properties
| Name | Value |
|---|---|
| tajo.driver | org.apache.tajo.jdbc.TajoDriver |
| tajo.url | jdbc:tajo://localhost:26002/default |
Dependencies
| Artifact | Excludes |
|---|---|
| org.apache.tajo:tajo-jdbc:0.11.0 |
How to use
Reference in paragraph
Start the paragraphs with the %jdbc, this will use the default prefix for connection. If you want to use other connection you should specify the prefix of it as follows %jdbc(prefix):
%jdbc
SELECT * FROM db_name;
or
%jdbc(prefix)
SELECT * FROM db_name;
Apply Zeppelin Dynamic Forms
You can leverage Zeppelin Dynamic Form inside your queries. You can use both the text input and select form parametrization features
%jdbc(prefix)
SELECT name, country, performer
FROM demo.performers
WHERE name=''
Bugs & Reporting
If you find a bug for this interpreter, please create a JIRA ticket.