Zeppelin Interpreter is a language backend. For example to use scala code in Zeppelin, you need scala interpreter. Every Interpreter belongs to an InterpreterGroup. InterpreterGroup is a unit of start/stop interpreter. Interpreters in the same InterpreterGroup can reference each other. For example, SparkSqlInterpreter can reference SparkInterpreter to get SparkContext from it while they're in the same group.
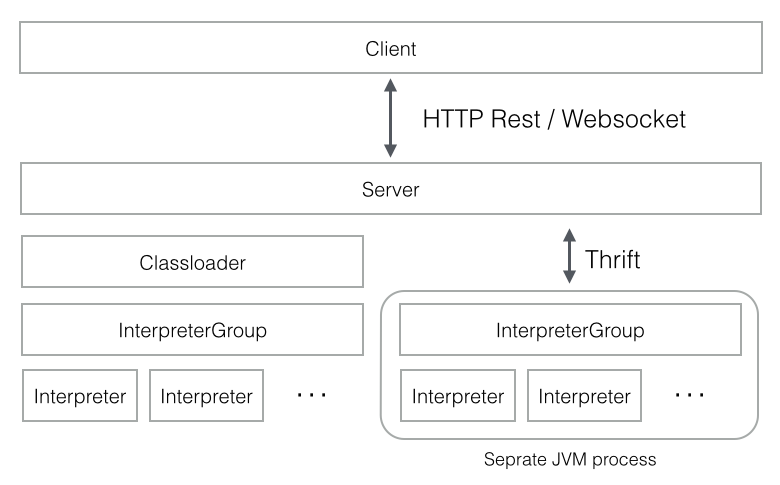
All Interpreters in the same interpreter group are launched in a single, separate JVM process. The Interpreter communicates with Zeppelin engine via thrift.
Creating a new interpreter is quite simple. Just extend org.apache.zeppelin.interpreter abstract class and implement some methods.
You can include org.apache.zeppelin:zeppelin-interpreter:[VERSION] artifact in your build system.
Your interpreter name is derived from the static register method
static {
Interpreter.register("MyInterpreterName", MyClassName.class.getName());
}
The name will appear later in the interpreter name option box during the interpreter configuration process.
The name of the interpreter is what you later write to identify a paragraph which should be interpreted using this interpreter.
%MyInterpreterName
some interpreter spesific code...
Once you have build your interpreter, you can place your interpreter under directory with all the dependencies.
[ZEPPELIN_HOME]/interpreter/[INTERPRETER_NAME]/
To configure your interpreter you need to follow these steps:
create conf/zeppelin-site.xml by copying conf/zeppelin-site.xml.template to conf/zeppelin-site.xml
Add your interpreter class name to the zeppelin.interpreters property in conf/zeppelin-site.xml
Property value is comma separated [INTERPRETERCLASSNAME] for example,
<property>
<name>zeppelin.interpreters</name>
<value>org.apache.zeppelin.spark.SparkInterpreter,org.apache.zeppelin.spark.PySparkInterpreter,org.apache.zeppelin.spark.SparkSqlInterpreter,org.apache.zeppelin.spark.DepInterpreter,org.apache.zeppelin.markdown.Markdown,org.apache.zeppelin.shell.ShellInterpreter,org.apache.zeppelin.hive.HiveInterpreter,com.me.MyNewInterpreter</value>
</property>
start zeppelin by running ./bin/zeppelin-deamon start
in the interpreter page, click the +Create button and configure your interpreter properties. Now you are done and ready to use your interpreter.
Note that the interpreters shipped with zeppelin have a default configuration which is used when there is no zeppelin-site.xml.
Inside of a notebook, %[INTERPRETER_NAME] directive will call your interpreter. Note that the first interpreter configuration in zeppelin.interpreters will be the default one.
for example
%myintp
val a = "My interpreter"
println(a)
Inside of a notebook, %[INTERPRETER_GROUP].[INTERPRETER_NAME] directive will call your interpreter. Note that the first interpreter configuration in zeppelin.interpreters will be the default one.
You can omit either [INTERPRETER_GROUP] or [INTERPRETER_NAME]. Omit [INTERPRETER_NAME] selects first available interpreter in the [INTERPRETER_GROUP]. Omit '[INTERPRETER_GROUP]' will selects [INTERPRETER_NAME] from default interpreter group.
For example, if you have two interpreter myintp1 and myintp2 in group mygrp,
you can call myintp1 like
%mygrp.myintp1
codes for myintp1
and you can call myintp2 like
%mygrp.myintp2
codes for myintp2
If you omit your interpreter name, it'll selects first available interpreter in the group (myintp1)
%mygrp
codes for myintp1
You can only omit your interpreter group when your interpreter group is selected as a default group.
%myintp2
codes for myintp2
Check some interpreters shipped by default.